About Geekflare Scraping API v2
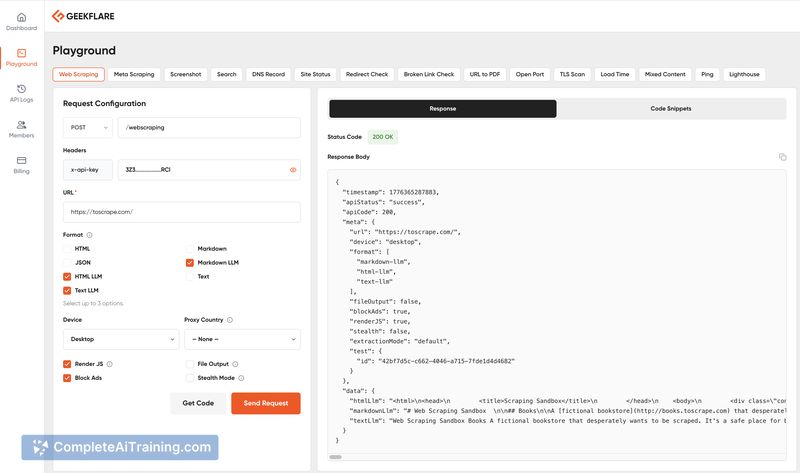
Geekflare Scraping API v2 is an API that extracts web page content and returns outputs optimized for large language models. It provides LLM-specific formats such as markdown-llm, text-llm, and html-llm while stripping navbars, footers, ads, and scripts to return only the primary content.
Review
Geekflare Scraping API v2 focuses on producing clean, compact content for use in retrieval-augmented generation and other LLM-driven workflows. By reducing extraneous HTML and offering structured LLM formats, it aims to lower token usage and improve response times for downstream models.
Key Features
- LLM-optimized output formats: markdown-llm, text-llm, and html-llm that remove non-essential page elements.
- Automated DOM cleaning using semantic HTML analysis and content-density scoring to isolate primary content blocks.
- Support for traditional extraction formats (HTML, JSON, Markdown) alongside LLM-ready outputs.
- Claims up to 85% token savings versus raw HTML when using LLM-specific outputs, lowering model context costs.
Pricing and Value
There are free options available and the service follows a usage-based pricing approach for higher volumes; a promotional discount (10% off for three months) was offered at launch. The core value proposition is cost reduction for LLM-driven projects: smaller, cleaner payloads can reduce OpenAI/Anthropic token bills and shorten model latency, making this API attractive for teams that regularly ingest web content into LLMs.
Pros
- Outputs formatted specifically for LLM consumption, which can meaningfully cut token costs and speed up responses.
- DOM cleaning that does not rely on CMS-specific class names, improving consistency across different sites.
- Multiple output options (LLM formats plus JSON/HTML/Markdown) for flexible integration into pipelines.
- Easy API-first integration suitable for automated RAG pipelines and AI agents.
Cons
- Complex page constructs such as extensive tables, pre/code blocks, or unusual layouts can require extra validation or post-processing.
- Pages that rely heavily on client-side rendering or interactive JavaScript may need pre-rendering or additional handling to capture full content.
- High-volume scraping and enterprise needs can lead to notable costs under a usage-based model, so budget planning is important.
Overall, Geekflare Scraping API v2 is a practical choice for developers and teams building RAG pipelines, chat assistants, or any application that feeds web content into LLMs and wants to reduce token overhead. For cases that involve highly dynamic pages or specialized structured extraction, pairing this API with rendering and custom parsers will yield the best results.
Open 'Geekflare Scraping API v2' Website
Your membership also unlocks: