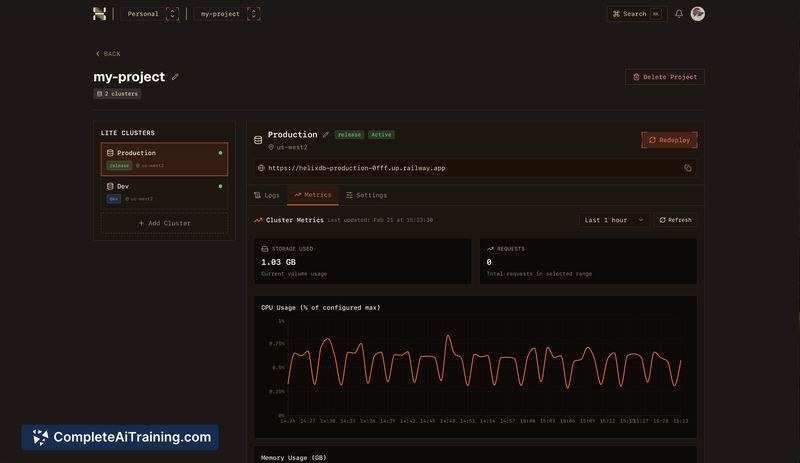
About HelixDB
HelixDB is an open-source OLTP database that combines graph and vector capabilities in a single engine, implemented in Rust. It launched as generally available after more than a year of development and targets workloads from indie developer agent memory to large-scale transactional systems.
Review
This review assesses HelixDB's core ideas, strengths, and limitations based on the project description and launch notes. I focus on its architecture choices, intended use cases, and what teams should expect when evaluating it for production.
Key Features
- Native graph plus vector support in one transactional engine, removing the need to stitch separate databases for traversal and similarity search.
- Built in Rust with performance and scalability as priorities; the project reports heavy query volumes and significant community interest.
- HelixQL, a query language influenced by functional graph approaches and SQL-style choices, aimed at expressive traversal and vector queries.
- Compiled queries that can limit how data is accessed, offering an additional layer for controlling query behavior.
- Open-source codebase with a public repository and an option for a hosted/cloud offering that includes built-in authentication.
Pricing and Value
HelixDB is available as a free, open-source project. That makes it attractive for prototyping, experimentation, and production use without licensing fees for the engine itself. For teams that prefer a managed option, the project mentions a hosted offering with authentication, which implies potential paid cloud tiers for operational convenience. The primary value is reducing operational complexity for agent-style memory and transactional graph/vector workloads by consolidating functionality into one engine.
Pros
- Combines graph traversal and vector similarity in a single system, simplifying architecture for hybrid use cases.
- Open-source and free to run, enabling inspection, customization, and community contributions.
- Rust implementation that targets low-level performance and concurrent workloads.
- Purpose-built query language and compiled queries that give developers expressive control over data access patterns.
- Positioned for OLTP-style graph/vector workloads and reports production-scale testing and usage.
Cons
- Not intended for OLAP or massive batch analytics; teams needing large-scale analytics should consider other systems for those workloads.
- Fine-grained user access controls for multi-tenant or application-level authorization are largely left to developers in self-hosted setups, which can increase implementation effort.
- The ecosystem and management tooling are still maturing compared with long-established databases, so some integrations and operational features may be missing initially.
HelixDB is well suited for developers and teams that need a transactional graph-plus-vector store-for example, agent memory, recommendation systems, or low-latency graph applications-who are comfortable operating an open-source engine or using an emerging hosted option. It's less appropriate for organizations primarily focused on large-scale analytics or those that require out-of-the-box, opinionated multi-tenant access controls without additional engineering work.
Open 'HelixDB' Website
Your membership also unlocks: