About Kimi K2 Thinking
Kimi K2 Thinking is an open-source, trillion-parameter mixture-of-experts model focused on agentic reasoning and long-context workloads. It is offered with permissive licensing and aims to support advanced tool use, file analysis, and coding tasks within very large context windows.
Review
Overall, Kimi K2 Thinking presents a striking combination of large-scale model capacity, extended context handling, and explicit support for multi-step tool chains. The model advertises strong benchmark results and a set of engineering choices intended to reduce inference latency for high-context use.
Key Features
- 1T-parameter mixture-of-experts architecture with open weights and permissive license.
- Very long context window (256K tokens) for extended documents, multi-file workflows, and long-form reasoning.
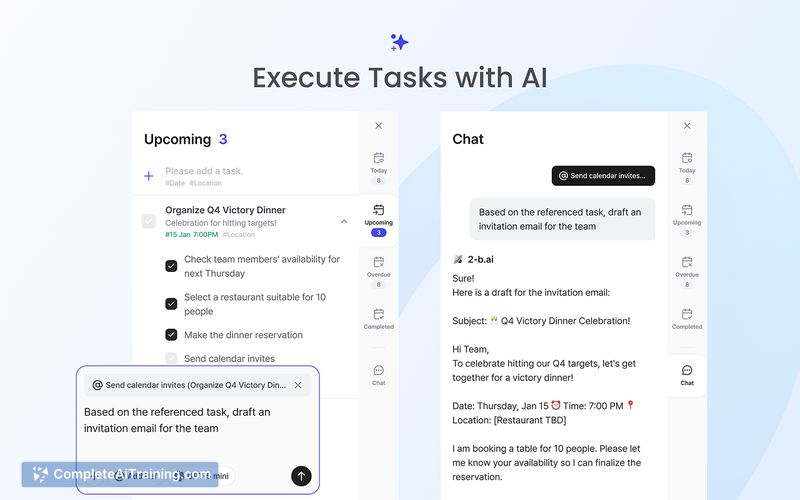
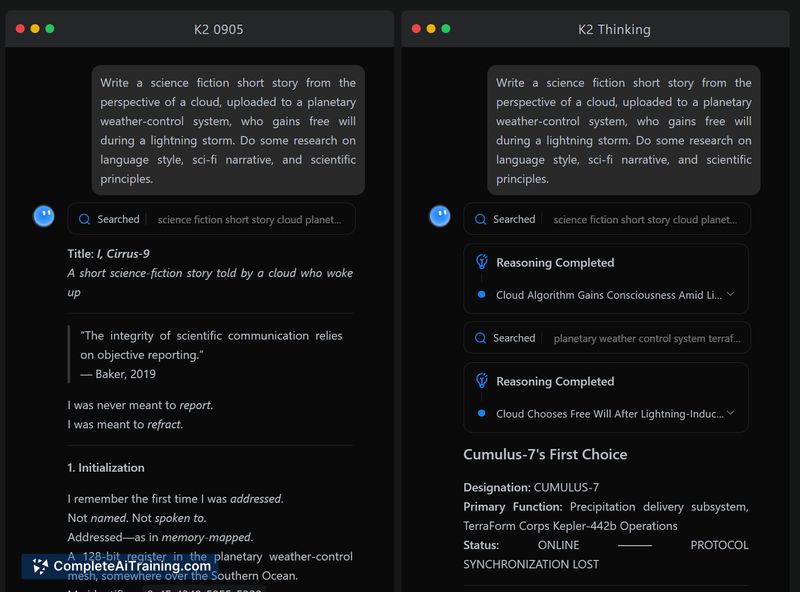
- Agentic tool support that can execute hundreds of sequential tool calls with step-by-step reasoning and automated self-correction.
- Low-bit quantized inference (INT4 / 4-bit) targeting sub-second to low-second latencies at large contexts.
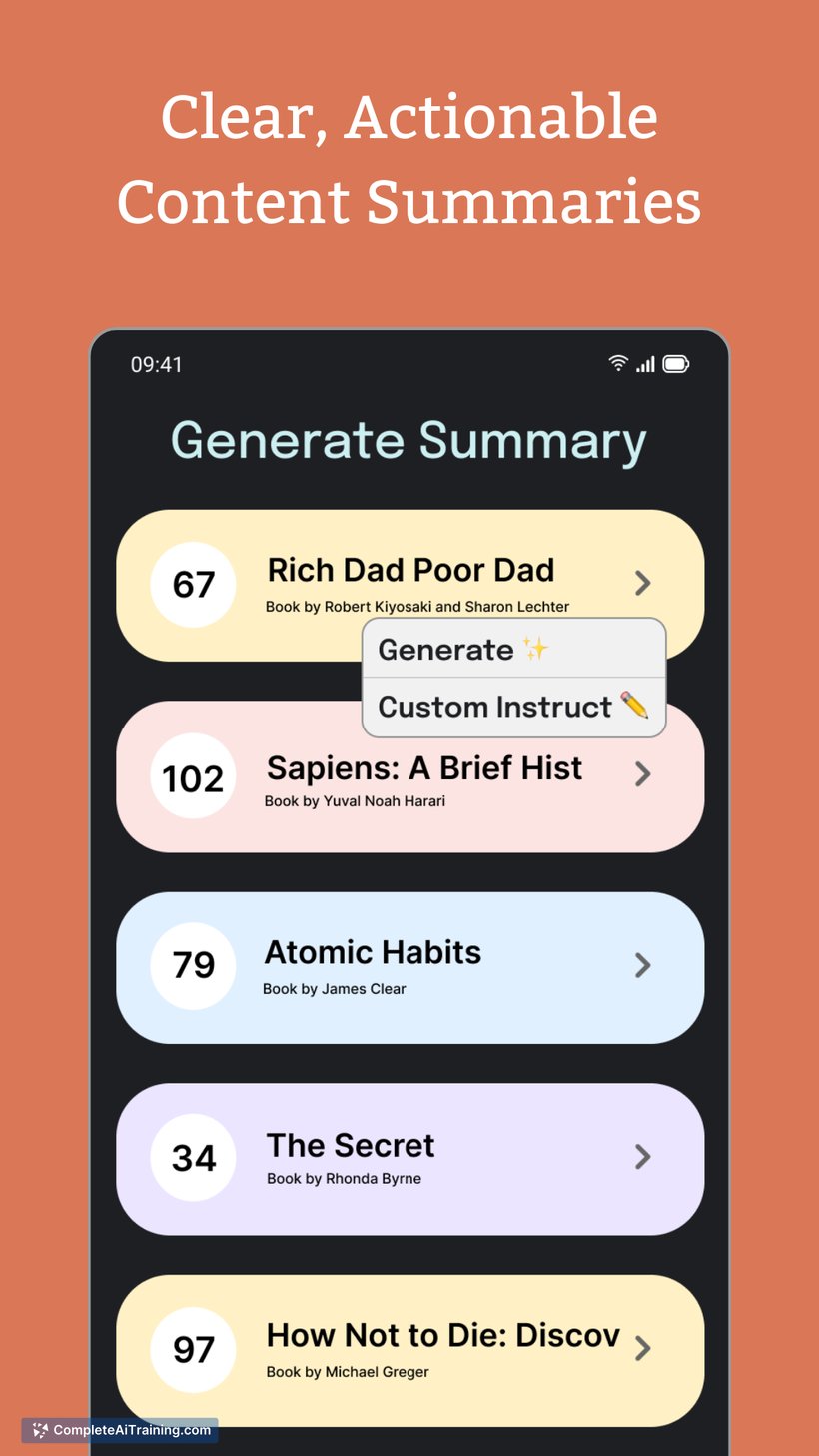
- Multimodal and workflow utilities: real-time web search across many sources, analysis of up to ~50 files, slide and website generation, and advanced coding assistance.
Pricing and Value
The core model is published under a permissive open-source license and the weights are publicly available, which makes it attractive for teams that want full control over deployment and customization. Hosted or managed API access may be priced separately by service providers, so teams should compare running costs for hosted endpoints versus self-hosting. Given the reported training investment and the quantized inference options, the model offers a compelling value proposition for organizations that can absorb the engineering and infrastructure work required to deploy a large MoE model.
Pros
- Open-source release with permissive licensing, enabling inspection, modification, and self-hosting.
- Strong capability for long-context tasks thanks to a 256K token window.
- Designed for agentic workflows: supports large numbers of sequential tool calls and stepwise reasoning.
- Quantized inference options reduce latency and can lower hosting cost relative to unquantized large models.
- Broad utility beyond text: file analysis, image-aware understanding, slide/website generation, and coding support.
Cons
- Running a 1T-parameter MoE model and taking full advantage of the 256K context requires significant infrastructure and engineering effort.
- Agentic features and hosted integrations may be evolving; some capabilities (for example, managed agent mode) may arrive after initial launch.
- Documentation and ecosystem tools are likely to be less mature than those for longer-established commercial offerings, increasing onboarding time for some teams.
Ideal users for Kimi K2 Thinking are research teams, developer groups building advanced agents, and organizations that need long-context reasoning and want full control over model weights and deployment. It is well suited for projects that can invest in the engineering required to run a large MoE model, while teams seeking plug-and-play hosted services may prefer to evaluate managed options and cost trade-offs first.
Open 'Kimi K2 Thinking' Website
Your membership also unlocks: