About LFM2-Audio
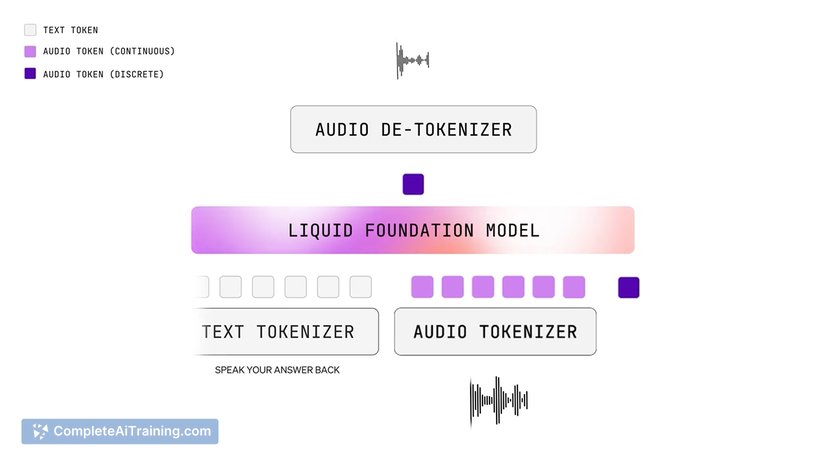
LFM2-Audio is a lightweight, multimodal audio foundation model built for real-time on-device conversational audio. It unifies audio analysis and generation into a single compact system, capable of speech-to-speech, speech-to-text, and text-to-speech in one model.
Review
In practice, LFM2-Audio is intended to simplify the traditional voice pipeline by replacing separate STT, LLM, and TTS components with a single model. The implementation targets low latency and local execution, positioning itself for applications where speed and privacy are priorities.
Key Features
- Unified voice stack: handles speech-to-speech, speech-to-text, and text-to-speech within one model.
- Compact architecture: a 1.5B-parameter model that fits a small footprint for edge deployment.
- Low latency: reported sub-100ms response times for on-device inference.
- On-device focus: intended to run locally to reduce data transmission and improve privacy.
- Efficient hybrid design: based on an architecture that claims improved CPU performance (up to ~2x vs. a comparable model) and state-of-the-art results for its size.
Pricing and Value
The tool is listed as free at launch, which lowers the barrier for experimentation and prototyping. Value is strongest for developers and product teams who need fast, private audio interactions on-device without the ongoing costs of cloud inference. That said, integration, testing across platforms, and potential hosting (if running in the cloud) can introduce additional development or infrastructure effort.
Pros
- Single-model approach reduces system complexity and integration overhead compared with chaining STT + LLM + TTS.
- Low on-device latency makes it well suited for real-time conversational experiences.
- Small model size and emphasis on efficiency enable deployment on constrained hardware.
- Free entry point encourages experimentation and early adoption.
- On-device execution supports stronger user privacy by keeping audio processing local.
Cons
- Smaller model size (1.5B) may trade off some fidelity or nuance compared with much larger cloud models for certain audio tasks.
- Platform support and tooling maturity are not yet fully established; additional engineering may be required to run on specific mobile or embedded targets.
- Documentation and ecosystem resources could be limited early in the launch, making advanced customization or debugging more time-consuming.
Overall, LFM2-Audio is a compelling option for teams that need low-latency, private voice interactions on-device-for example, mobile apps, embedded assistants, or products with strict data-control requirements. It suits developers and small teams looking to prototype or ship conversational audio features without relying on cloud-only pipelines, while teams that require the highest possible audio fidelity or broad language coverage may want to evaluate trade-offs before committing.
Open 'LFM2-Audio' Website
Your membership also unlocks: