About Mercury 2
Mercury 2 is a second-generation diffusion large language model that replaces sequential decoding with parallel refinement to generate tokens simultaneously. It targets low-latency production use cases by delivering high token throughput and reasoning-oriented outputs.
Review
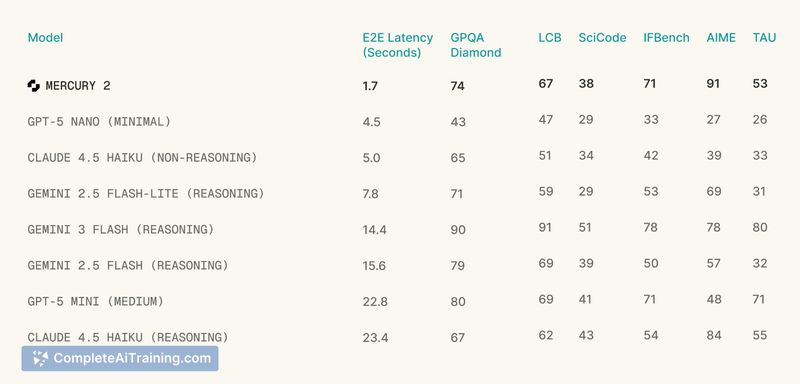
Mercury 2 positions itself as a reasoning-focused diffusion LLM that emphasizes inference speed and compatibility with existing APIs. The model claims over 1,000 tokens per second and an OpenAI-compatible API, which makes it easy to test in existing workflows while offering an alternative to autoregressive approaches.
Key Features
- Parallel refinement generation: tokens are produced in a simultaneous refinement process instead of left-to-right decoding.
- High throughput: reported rates exceed 1,000 tokens per second, reducing latency for multi-step pipelines.
- Reasoning-oriented outputs: positioned for tasks that benefit from stronger stepwise reasoning and coding quality.
- OpenAI-compatible API surface for straightforward integration with existing code and tools.
- Free options and early access channels to try the model before full production adoption.
Pricing and Value
Mercury 2 offers free options and an early access pathway, with an API designed to be compatible with common integrations. The main value proposition is faster inference, which can lower per-request latency and potentially reduce infrastructure costs by completing tasks more quickly. Exact pricing details and cost comparisons will depend on usage patterns and should be evaluated during a trial to determine real-world savings.
Pros
- Very high token throughput for low-latency applications and multi-step agent pipelines.
- Parallel generation approach can reduce end-to-end latency compared with sequential decoding.
- API compatibility simplifies migration from other providers and shortens integration time.
- Reported competitive quality on coding and reasoning tasks.
Cons
- Diffusion-based LLMs are a newer approach, so tooling, community knowledge, and best practices are still developing.
- Early access availability may limit immediate production deployment for some teams.
- Potential differences in determinism and control compared with mature autoregressive models; teams should validate behavior for their specific workloads.
Mercury 2 is best suited for teams building agentic loops, real-time conversational or voice systems, and production services where cumulative latency matters. Developers who want a fast, OpenAI-compatible option and are comfortable experimenting with diffusion LLM behavior will see the most benefit. Conducting a pilot on representative tasks is recommended to confirm fit and cost-effectiveness.
Open 'Mercury 2' Website
Your membership also unlocks: