About Mesh LLM
Mesh LLM pools spare compute into an auto-configured peer-to-peer inference cloud that lets you serve many open models and access private models from anywhere. It supports sharing compute with others and enables agents to collaborate across the mesh.
Review
Mesh LLM aims to simplify self-hosted inference by auto-configuring node discovery, model placement, and exposing a standard OpenAI-compatible endpoint so existing agent tooling can work without a custom client. That approach reduces manual operational overhead, but the reliance on spare capacity introduces trade-offs around continuity and error handling that teams should test for.
Key Features
- Auto-configured peer-to-peer mesh for inference node discovery and coordination
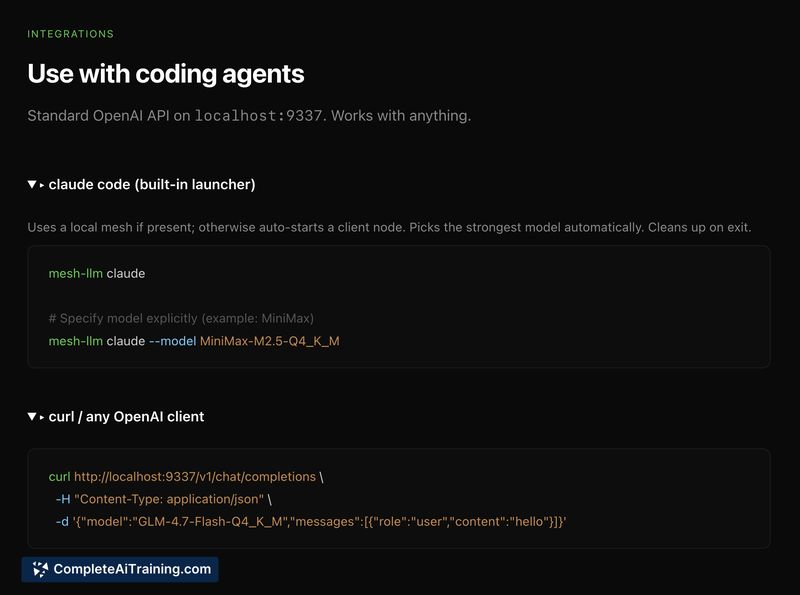
- OpenAI-compatible API endpoint for easy integration with existing agents and tooling
- Pooling of spare compute to run multiple open models and share capacity with others
- Access to private models from anywhere within the mesh
- Support for agents to collaborate p2p, letting distributed workflows call models across nodes
Pricing and Value
Mesh LLM is listed as free at launch, which makes it attractive for experimentation and early adoption. The core value is operational convenience: fewer manual steps to run self-hosted inference and immediate compatibility with tools expecting an OpenAI-style endpoint. However, costs to consider include the maintenance of participating machines, networking overhead, and potential engineering effort to harden failure and retry behavior for production use.
Pros
- Simplifies setup by auto-configuring a p2p inference mesh and exposing a familiar API
- Makes it straightforward to run and share multiple open models and private models
- Enables agent collaboration across nodes without building custom clients
- Good entry point for teams with spare machines to leverage existing capacity
- Free launch lowers the barrier to try the system
Cons
- Spare capacity is inherently variable, so node availability can be volatile under real workloads
- Handling partial failures and retries across a growing mesh requires careful engineering to avoid surfacing errors to clients
- May require additional monitoring and operational practices before depending on it for strict production SLAs
Mesh LLM is best suited for developers, research groups, and small teams that want to experiment with self-hosted inference, share idle machines, or run private models without building custom integrations. Teams with strict uptime or latency requirements should evaluate failure and retry behavior under realistic multi-agent workflows before committing it to production.
Open 'Mesh LLM' Website
Your membership also unlocks: