About Mistral Medium 3.5
Mistral Medium 3.5 is a 128B dense language model that combines instruction-following, reasoning, and coding capabilities in a single set of weights. It offers a very large 256k context window and configurable reasoning effort per request, with open weights available for self-hosted deployment.
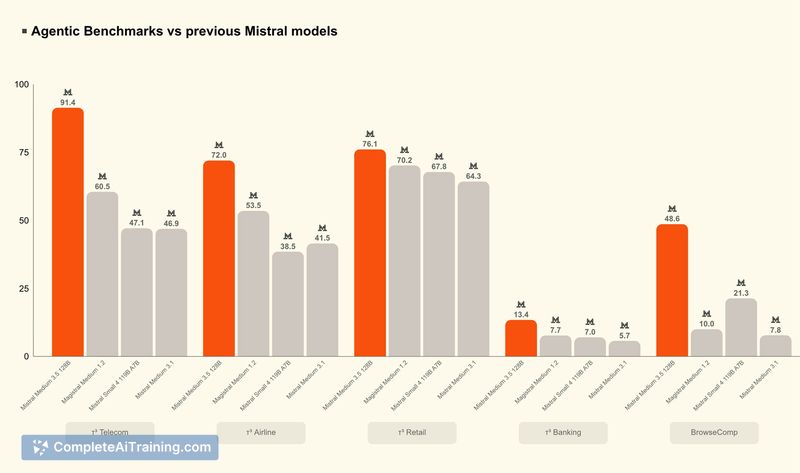
Review
This release aims to provide a high-capability model that can run on modest infrastructure while supporting tasks from quick chat replies to long-horizon coding and reasoning jobs. Public benchmarks report competitive performance, and the model's distribution includes open weights under a permissive license for teams that want to run or tune it on-premises.
Key Features
- 128B dense model that merges instruction-following, coding, and reasoning into one set of weights
- 256k token context window for long documents, codebases, and multi-step workflows
- Configurable reasoning effort per call to trade off latency and depth of computation
- Open weights released under a modified MIT-style license for local use and fine-tuning
- Self-hostable on relatively small GPU setups and provided as containers for common GPU platforms
Pricing and Value
API pricing is offered on a per-token basis (example rates reported at $1.5 per million input tokens and $7.5 per million output tokens). The availability of open weights is a key part of the value proposition: teams that can run the model on their own hardware can avoid ongoing API fees and perform custom fine-tuning or auditing. The configurable reasoning effort helps control cost and latency for mixed workloads by applying deeper compute only when needed.
Pros
- Single model that covers instruction-following, coding, and reasoning workloads, reducing complexity of model selection
- Very large context window useful for long-form code, documents, and chaining multi-step tasks
- Open weights enable on-prem deployment, auditing, and customization
- Configurable reasoning effort provides a practical knob for cost and performance trade-offs
- Can be run on modest GPU counts relative to models of similar capability
Cons
- Self-hosting still requires non-trivial GPU resources and systems engineering to get optimal performance
- Open-weight distribution uses a modified license that teams should review for compatibility with their use case
- Ecosystem and tooling around a new flagship model may lag more established options in some integrations
Overall, this model is well suited for backend and ML engineers or teams that need an open-weight option for agentic pipelines, coding assistants, or on-prem inference where control and customizability matter. It makes particular sense for groups prepared to invest in the infrastructure and integration work required to host and tune a large model.
Open 'Mistral Medium 3.5' Website
Your membership also unlocks: