About ml-intern
ml-intern is an open-source AI agent that automates many post-training tasks for large language models. It can read research papers, prepare or create datasets, run training jobs, diagnose failures, and iterate experiments with minimal human supervision.
Review
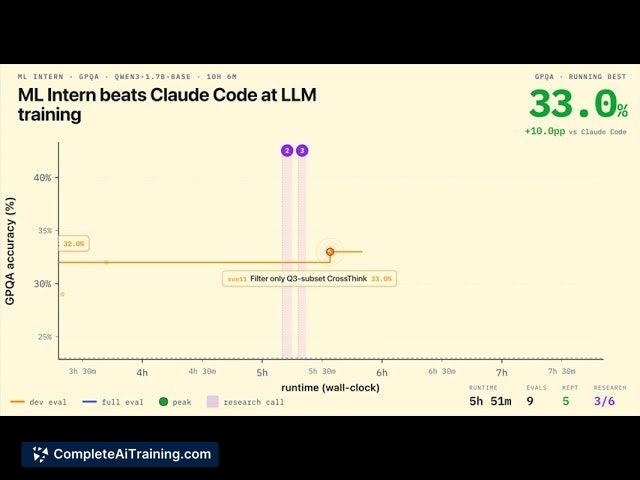
ml-intern aims to reproduce a research-style loop in an automated fashion, turning common researcher workflows into an agent-driven pipeline. Early results reported during launch include notable gains on established benchmarks (for example, +22 points on GPQA in about 10 hours and a +60% improvement on HealthBench), which highlight its potential impact on model fine-tuning and evaluation.
Key Features
- Automated literature and citation parsing: discovers and reads relevant research, follows citations, and extracts methods or datasets to try.
- Dataset engineering and synthesis: inspects, repairs, reformats, and can generate synthetic data to augment training sets.
- Training orchestration: launches jobs on available GPUs or cloud job services, monitors runs, reads evaluation outputs, and diagnoses failures.
- Iterative experimentation: runs multiple SFT/ablation experiments, evaluates results, and iterates without manual orchestration.
- Multiple interfaces: available as a command-line tool and a web/mobile app for convenient access.
Pricing and Value
The project is offered as a free, open-source tool. While the software itself does not carry a direct charge, users should expect compute costs when running training jobs on local hardware or cloud services. At launch, early users received provisioned credits to get started, but sustained use will typically require budgeting for GPU time and any cloud job service fees.
Pros
- Saves time by automating repetitive research and post-training steps that normally require hands-on effort.
- Demonstrated capability to achieve substantial benchmark improvements in short timeframes in early tests.
- Open-source code allows for inspection, customization, and integration into existing workflows.
- Supports both CLI and web interfaces, making it accessible for different working styles.
- Handles both data preparation and training orchestration, reducing manual pipeline glue work.
Cons
- Training and experimentation remain resource intensive; meaningful use often requires access to GPUs and cloud credits.
- Outputs and data changes should be carefully reviewed-automated dataset generation or fixes can introduce subtle issues, especially in regulated domains like healthcare.
- Because the agent runs complex sequences autonomously, debugging unexpected behaviors or reproducing exact runs can be more involved than with manual pipelines.
Overall, ml-intern is best suited for ML researchers, AI engineers, and teams that have access to GPU resources and want to speed up iterative fine-tuning and evaluation cycles. It can be a strong productivity booster for experienced practitioners, but organizations should plan for compute costs and put review processes in place when applying it to sensitive or production settings.
Open 'ml-intern' Website
Your membership also unlocks: