About Ollama v0.19
Ollama v0.19 is an update to a tool for running large language models locally, with a focus on macOS and Apple Silicon. This release emphasizes faster on-device inference and improved session responsiveness for coding and multi-turn agent workflows.
Review
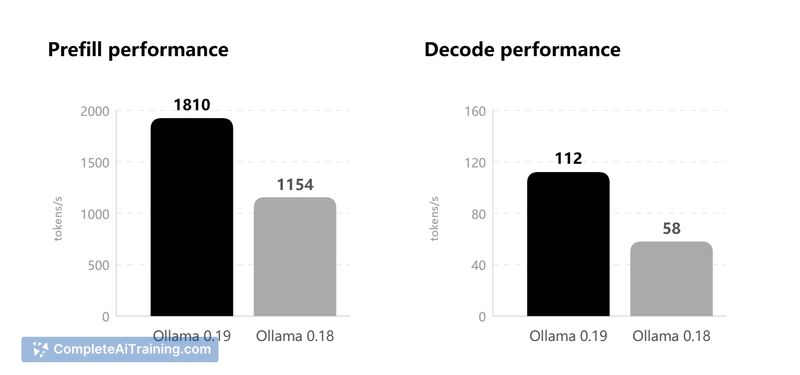
This release reimplements Apple Silicon inference on top of the MLX framework, delivering noticeable speed improvements on M-series machines and better use of unified memory. It also adds NVFP4 support and a reworked key-value cache with reuse, snapshots, and smarter eviction, which together reduce cold starts and improve multi-conversation agent performance.
Key Features
- MLX-native inference for Apple Silicon to take advantage of unified memory and GPU Neural Accelerators.
- NVFP4 quantization support to bring local inference closer to production-level performance.
- Reworked KV cache with reuse across conversations, intelligent checkpoints, snapshots, and smarter eviction.
- More responsive sessions for coding assistants and branching agent workflows.
- macOS-first support with Windows and Linux scheduled to arrive later.
Pricing and Value
The release is listed as free and carries open-source tags, making it easy to try without upfront cost. The main value comes from running models locally-avoiding third-party API fees and keeping data on-device-which is attractive for privacy-focused workflows and offline prototyping. Expect the best returns on systems with M-series chips and ample unified memory; large models will still demand significant RAM and storage.
Pros
- Significant speed and latency improvements on Apple Silicon thanks to MLX integration.
- NVFP4 support reduces the gap between local inference and production behavior.
- Smarter KV cache reduces repeated cold starts for multi-turn or branching agent tasks.
- Easy local deployment and no dependency on external API keys for many workflows.
- Free and open-source-friendly for experimentation and integration.
Cons
- Primary optimizations target macOS and M-series hardware; other platforms lag behind for now.
- Large models and heavy agentic workflows require substantial memory (32GB+ recommended for some models).
- Image generation features are still not available at this time.
Ollama v0.19 is best suited for developers and makers who run local LLMs on Apple Silicon and need faster, more responsive agent or coding workflows without relying on cloud APIs. Users on non-macOS platforms or those with limited hardware resources may want to wait for broader platform support or plan for additional memory before upgrading.
Open 'Ollama v0.19' Website
Your membership also unlocks: