About OpenAI GPT-4o Audio Models
OpenAI GPT-4o Audio Models are advanced AI tools designed to process and generate audio content using natural language understanding. These models enable a wide range of audio-related applications, including transcription, audio synthesis, and interactive voice experiences, leveraging the capabilities of GPT-4 architecture.
Review
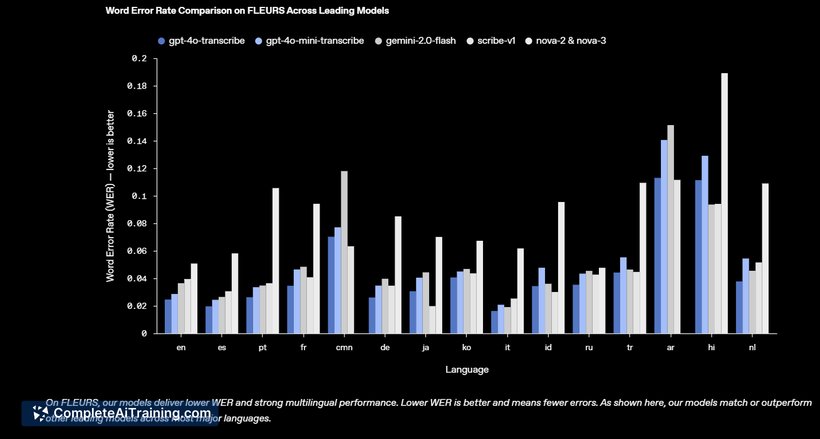
The OpenAI GPT-4o Audio Models offer a versatile approach to handling audio data with AI. They provide users with efficient and accurate audio-to-text conversions as well as text-to-audio generation, making them suitable for various professional and creative tasks. The integration of language understanding with audio processing sets these models apart from many traditional audio tools.
Key Features
- High-quality transcription with support for multiple languages and dialects
- Text-to-speech synthesis that produces natural and clear audio outputs
- Real-time audio interaction capabilities for conversational AI applications
- Ability to handle noisy or low-quality audio inputs with improved accuracy
- Flexible API integration for seamless incorporation into existing workflows
Pricing and Value
The pricing for OpenAI GPT-4o Audio Models generally follows a usage-based model, with costs determined by the amount of audio processed or generated. This pay-as-you-go structure allows users to scale their usage according to their needs without upfront commitments. Given the quality and flexibility of the models, the value proposition is strong for businesses and developers seeking reliable audio AI solutions without investing heavily in custom development.
Pros
- Accurate and fast transcription suitable for diverse audio sources
- Natural-sounding audio generation that supports multiple voices and languages
- Easy integration through comprehensive API support
- Handles challenging audio conditions effectively
- Supports real-time interaction, enhancing user engagement possibilities
Cons
- Costs can increase significantly with high-volume usage
- Some specialized audio domains may require additional fine-tuning for optimal results
- Dependent on internet connectivity for API access, which may limit offline use
Overall, OpenAI GPT-4o Audio Models are well suited for developers, businesses, and content creators looking to incorporate advanced audio processing into their applications. They perform especially well in scenarios requiring accurate transcription and realistic audio generation, such as customer service automation, podcast production, and educational content development.
Open 'OpenAI GPT-4o Audio Models' Website
Your membership also unlocks: