About Papr
Papr is a predictive memory and context intelligence API built for AI agents and analytics interfaces. It links conversational history, documents, and structured data into a combined vector index and knowledge graph to make context retrieval more accurate and faster.
Review
Papr aims to reduce AI hallucinations by providing a single memory layer that unifies retrieval-augmented workflows and long-term memory. It offers flexible query options (GraphQL and natural language), built-in access controls for multi-tenant setups, and both an open-source local edition and a cloud edition for production use.
Key Features
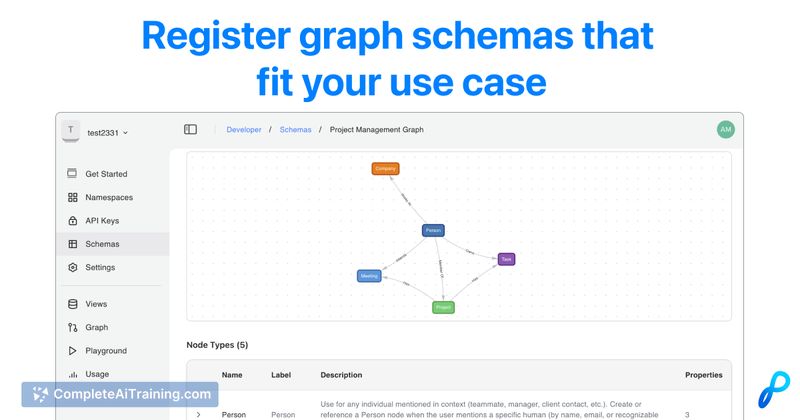
- Predictive Memory Graph that connects related context across data sources
- Combined vector index plus knowledge graph for richer retrieval
- GraphQL and natural language query support for developers and UIs
- Built-in ACLs and permission controls for secure multi-tenant deployments
- Open-source local deployment option alongside a managed cloud edition
Pricing and Value
Papr is available as an open-source project for self-hosted deployments, which can be used at no license cost for local development and private installations. The cloud edition follows a hosted model with tiered plans or usage-based billing for production workloads, with enterprise options likely for advanced security and scale. For teams that need unified memory and retrieval in one API, the combination of graph-aware indexing and fast retrieval (reported >91% accuracy and sub-100ms latency on benchmarks) can deliver strong value by reducing incorrect model outputs and simplifying infrastructure.
Pros
- High retrieval accuracy and low latency reported on benchmarks
- Unifies RAG and memory into a single API, reducing the need for separate systems
- Flexible querying via GraphQL or natural language, useful for both agents and analytics UIs
- Privacy and tenancy controls make it suitable for multi-customer environments
- Open-source option lets teams run locally and inspect internals
Cons
- Relatively new offering, so community resources and third-party integrations are still growing
- Custom schema and graph design can add upfront implementation complexity for teams unfamiliar with graph models
- Cloud pricing at large scale may be a concern without clear public pricing details
Overall, Papr is a good fit for engineering teams building AI agents, conversational systems, or analytics interfaces that need accurate, low-latency access to connected context and fine-grained access controls. Teams that prefer self-hosting or require strict data isolation will appreciate the open-source option, while those wanting a managed path can evaluate the cloud edition for production scale.
Open 'Papr' Website
Your membership also unlocks: