About Parallax by Gradient
Parallax by Gradient is a framework for serving large language models across multiple devices by pooling GPU resources, allowing models to run beyond the limits of a single machine. It supports heterogeneous setups (Mac and PC mixes) and aims to make local, private model hosting more scalable and accessible.
Review
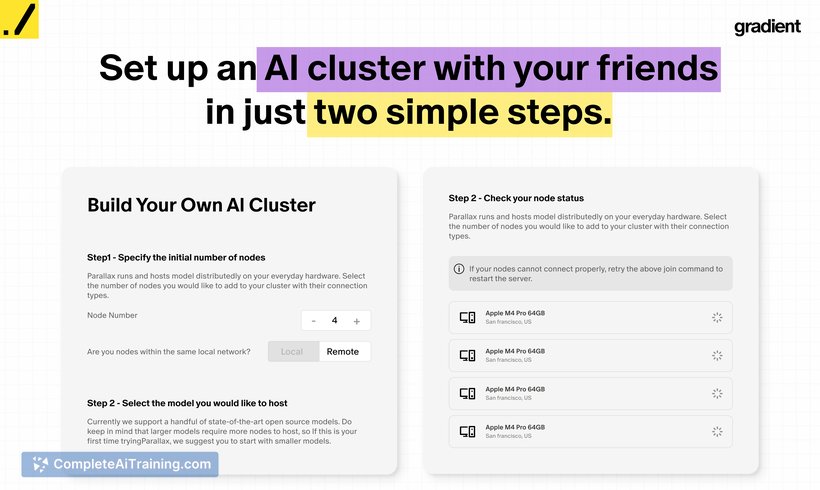
This tool focuses on distributed local inference: it lets you create an AI cluster from available devices on a LAN or across the internet so larger models can be executed without relying on a single, high-end GPU. The project launched as a free, open-source offering and already lists support for many popular open models and several deployment modes.
Key Features
- Distributed model serving across devices, sharing GPU resources to run larger LLMs than a single device could handle.
- Three hosting modes: Local host (single machine), Co-Host (LAN-based sharing), and Global Host (WAN-based across locations).
- Cross-platform support for Mac and PC mixes, with runs that do not require a public IP and include traceability of jobs.
- Launch support for 40+ open models ranging from smaller (0.6B) to much larger, including some MoE-class configurations.
- Open-source codebase with a public repository for contributions and issue tracking (GitHub repo).
Pricing and Value
Parallax by Gradient is offered free to use and distributed under an open-source approach. The value proposition is primarily in enabling private, local inference that can scale by pooling idle devices, which is attractive for hobbyists, research groups, and organizations that prefer self-hosted models for privacy or cost control. Users should weigh the savings versus cloud alternatives, since achieving large-scale performance requires a sufficient set of participating devices and potentially some networking setup.
Pros
- Free and open-source - easy to inspect, modify, and contribute to the codebase.
- Lets multiple, heterogeneous devices collaborate so models larger than a single GPU can be run locally.
- Flexible deployment modes (local, LAN, WAN) and no requirement for a public IP simplifies many setups.
- Wide initial model support and a roadmap for system-level improvements and inference optimizations.
Cons
- Still early in development: orchestration logic and some features (for example, automatic node rebalancing) are being refined or planned.
- Requires a moderate level of technical familiarity to set up and manage a multi-node cluster, which could be a hurdle for non-technical users.
- Performance in real-world multi-node scenarios will depend on network quality and the mix of hardware available, so results can vary.
Parallax by Gradient is best suited for developers, researchers, and small teams who want private, scalable local inference and have access to multiple devices they can network together. Those seeking a plug-and-play cloud-hosted service or who lack spare compute resources may find a cloud solution more convenient, but Parallax offers a compelling alternative for self-hosted experimentation and development.
Open 'Parallax by Gradient' Website
Your membership also unlocks: