About Phi-4-reasoning-vision
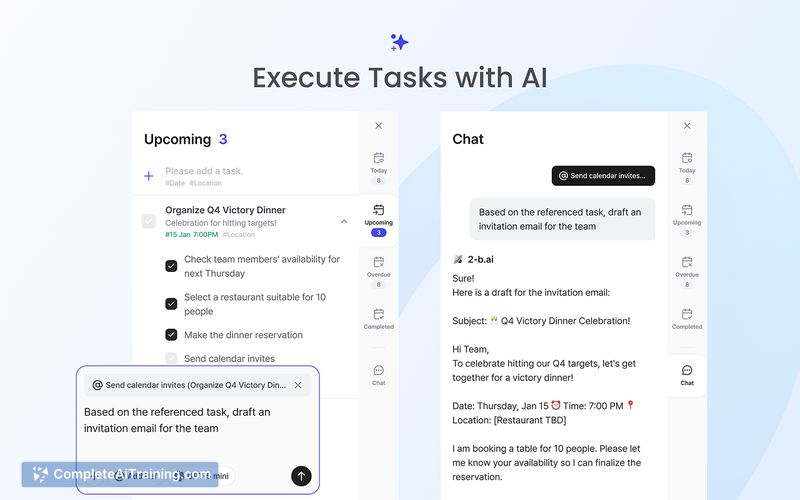
Phi-4-reasoning-vision is an open-weight 15B multimodal model built on a mid-fusion architecture. It blends fast perception for straightforward visual inputs with deeper chain-of-thought processing for harder reasoning tasks, and is positioned for use in GUI agents, math, science, and code workflows.
Review
Phi-4-reasoning-vision targets users who need a compact multimodal model that balances speed and depth of reasoning. It aims to handle high-resolution screen content efficiently while switching to more deliberate internal reasoning when problems require it.
Key Features
- 15B open-weight multimodal model using a mid-fusion design for visual + text inputs.
- Adaptive processing that favors fast direct perception on simple inputs and chain-of-thought for harder problems.
- Trained on a large multimodal corpus (reported around 200B multimodal tokens) to improve reasoning across images and text.
- Optimized for GUI and screen-based agent tasks, with attention to handling high-resolution displays.
- Available as open-source and distributed via Hugging Face and Azure AI Foundry.
Pricing and Value
The model is offered as open-weight and listed as free on its launch page, which makes it accessible for experimentation and integration without licensing fees. For teams that need a balance between capability and resource use, the 15B size can provide strong reasoning capability while being more practical to run than many much larger models; reports indicate it can be practical on a single 24GB GPU for many use cases. Hosting options on Hugging Face and Azure AI Foundry add deployment flexibility for different operational needs.
Pros
- Good mix of fast perception and deeper reasoning, reducing wasted compute on simple tasks.
- Multimodal training supports tasks that combine images and text, including screen reading and GUI automation.
- Open-weight and free availability lowers the barrier for research and product integration.
- Designed with high-resolution inputs in mind, which benefits browser automation and testing scenarios.
Cons
- Smaller than the largest closed models, so some very large-scale benchmarks may still favor bigger alternatives.
- Effective deployment for production agents will often require task-specific fine-tuning and validation.
- When deep chain-of-thought is triggered frequently, latency and compute costs can increase compared with purely shallow approaches.
Overall, Phi-4-reasoning-vision is well suited for developers and researchers building GUI agents, browser automation, and multimodal reasoning tools who need a practical trade-off between capability and resource demands. It is a strong option for teams that want an open-weight model capable of handling high-resolution visual inputs and stepping up reasoning depth when tasks require it.
Open 'Phi-4-reasoning-vision' Website
Your membership also unlocks: