About RunInfra
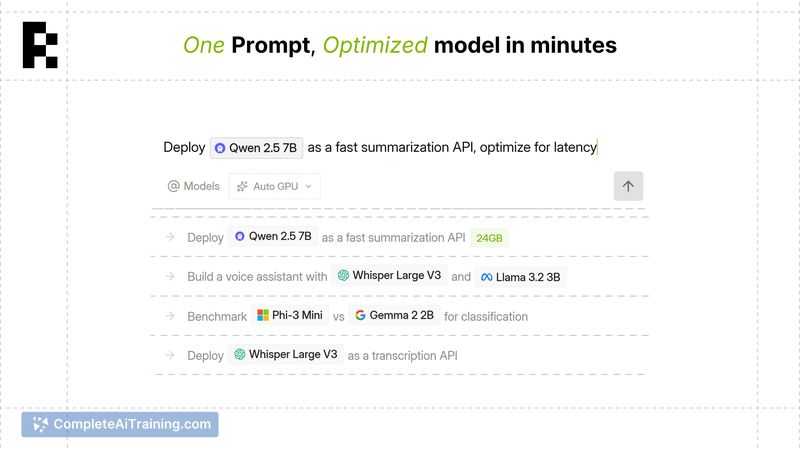
RunInfra converts plain language descriptions of open-source models into production APIs. The platform generates custom CUDA kernels to optimize deployment. Developers build voice, document search, vision, and model routing applications through a single chat interface.
Review
Manual GPU selection usually slows down AI deployment. RunInfra removes this configuration layer, translating natural language prompts directly into optimized backend code. While the system handles compute adjustments, developers can then focus on application logic.
Key Features
- Custom CUDA kernels generated by the Forge agent tune to specific models and hardware, avoiding generic hosting kernels.
- Users describe any open-source model or full application in plain text to create voice, vision, or document search pipelines.
- Swapping a deployed model triggers an automatic regeneration of kernels without requiring manual configuration changes.
- Infrastructure scales to zero when inactive, and developers can choose to run workloads on managed servers or their own GPUs.
Pricing and Value
RunInfra bills per million tokens processed. A scale-to-zero mechanism prevents inactive applications from incurring compute costs. Developers can also run the infrastructure on their own GPUs if they don't want managed hosting fees.
Pros
- Eliminates the need for manual vLLM tuning and GPU benchmarking during the initial deployment phase.
- Custom CUDA kernel generation targets the exact model and GPU combination, which reduces latency in multi-stage pipelines like voice processing.
- The system benchmarks hardware and quantizes models automatically, removing the need to write custom tuning scripts.
- Running applications on proprietary hardware remains an option for teams with existing GPU clusters.
Cons
- Auto-generated CUDA kernels carry inherent risks of subtle numerical errors or edge-case failures that require rigorous output diffing against reference implementations.
- The platform is not well suited for developers who need deep, manual control over low-level infrastructure configurations or custom dashboard metrics.
- Relying entirely on plain language descriptions limits the ability to fine-tune specific compiler flags or memory allocation parameters directly.
This tool fits teams building production voice pipelines where every stage requires lower latency. Engineers prioritizing cost optimization over manual server configuration will find the platform useful.
Open 'RunInfra' Website
Your membership also unlocks: