About SCRAPR
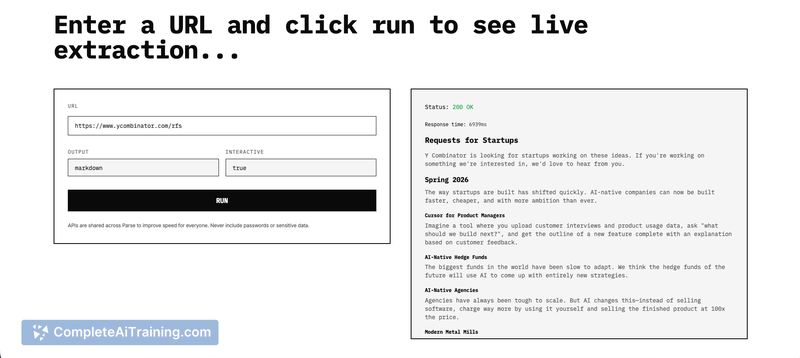
SCRAPR turns any website into an API by intercepting the network calls websites use and reconstructing clean structured data from those sources. It aims to avoid full browser rendering and traditional fragile HTML parsing, offering a no-code option that does not require API keys for the original sources.
Review
SCRAPR takes a different route from typical scrapers by targeting the same endpoints a site uses internally (fetch, axios, GraphQL) rather than relying on DOM selectors or running a headless browser. That approach makes it faster and often more stable on modern JavaScript-heavy sites, though there are still edge cases where site protections add complexity.
Key Features
- Network-call interception to discover and call internal data endpoints (fetch, axios, GraphQL).
- No-browser, no-code extraction with no need for source API keys in many cases.
- Fallback extraction from page structure when underlying endpoints change or disappear.
- Batch request support for processing multiple URLs in a single call, suited for pipelines.
- Lightweight and faster than spinning up a full browser for each scrape.
Pricing and Value
Public information indicates there are free options available, with the likely expectation of paid tiers for higher volume or enterprise needs. The value proposition centers on reducing maintenance and runtime costs compared with browser automation tools by providing faster, more stable structured outputs; teams should evaluate limits, quotas, and pricing details against expected volume before committing.
Pros
- Generally more stable than scrapers that depend on CSS selectors or DOM structure.
- Faster and lighter than solutions that require full browser automation.
- No-code entry and simple integration for pulling structured data into pipelines.
- Batch support makes it practical for larger data collection tasks.
- Fallback mode helps recover when upstream endpoints change.
Cons
- Sites that sign requests, use dynamic session tokens, or enforce strict protections can still pose challenges and may require additional handling.
- Publicly available pricing and rate limits are limited, so cost predictability requires clarification from the provider.
- Some very unusual or highly obfuscated sites may still need manual intervention or custom rules.
SCRAPR is a good fit for developers, analysts, and product teams that need reliable, structured data from modern websites without the overhead of browser-based scraping. It works well for data pipelines and automation where speed and reduced fragility matter, though teams scraping heavily protected or signed endpoints should plan for potential extra work or fallbacks.
Open 'SCRAPR' Website
Your membership also unlocks: