About SelfHostLLM
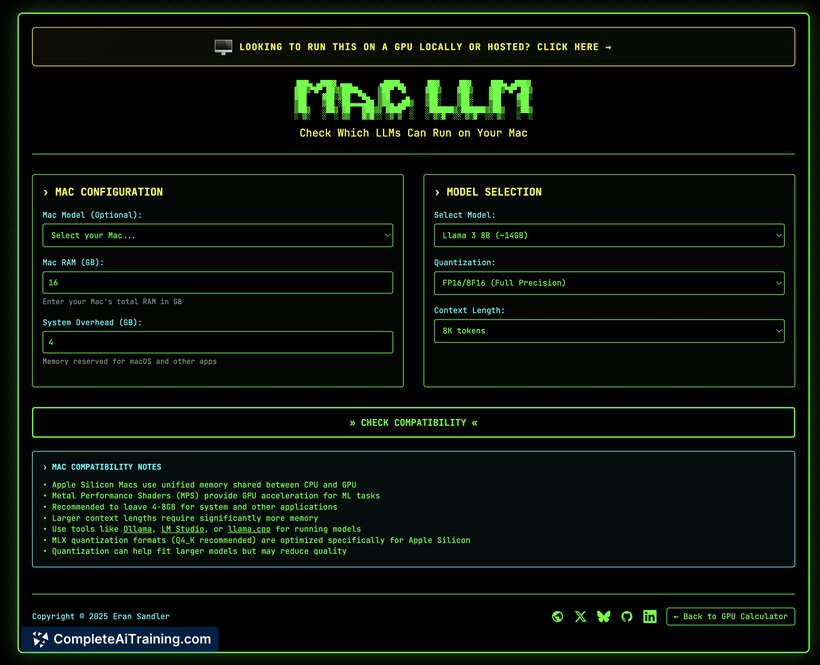
SelfHostLLM is a specialized tool designed to help users calculate GPU memory requirements and maximum concurrent requests for self-hosted large language model (LLM) inference. It supports a variety of popular models including Llama, Qwen, DeepSeek, and Mistral, allowing for more efficient AI infrastructure planning.
Review
SelfHostLLM offers a practical solution for developers and organizations looking to manage the hardware demands of running LLMs locally. By providing precise estimates based on custom configurations, it removes much of the uncertainty involved in resource allocation for self-hosted AI deployments.
Key Features
- GPU memory calculator tailored for LLM inference workloads.
- Support for multiple popular models such as Llama, Qwen, DeepSeek, and Mistral.
- Estimation of maximum concurrent requests to optimize usage without overprovisioning.
- Custom configuration options to fit diverse deployment scenarios.
- Availability of a Mac version, broadening accessibility for different users.
Pricing and Value
SelfHostLLM is offered as a free tool, which makes it accessible for developers and teams aiming to plan their AI infrastructure without upfront costs. Its value lies in helping users avoid overspending on GPU resources by providing accurate calculations tailored to specific LLMs and deployment needs.
Pros
- Free to use with open-source availability.
- Supports a wide range of LLMs, accommodating various use cases.
- Helps prevent unnecessary hardware expenditure through precise resource estimation.
- User-friendly interface with custom configuration options.
- Includes support for Mac users, expanding platform compatibility.
Cons
- Focuses solely on GPU memory and concurrency estimation, lacking broader infrastructure management features.
- May require some technical knowledge to configure models and interpret results effectively.
- Limited information on integration with other AI deployment tools or monitoring systems.
Overall, SelfHostLLM is well suited for developers, AI engineers, and teams planning to self-host language models who need reliable estimates of GPU requirements. It works best for users with some familiarity with LLM deployments who want to optimize hardware investments and avoid common pitfalls related to resource allocation.
Open 'SelfHostLLM' Website
Your membership also unlocks: