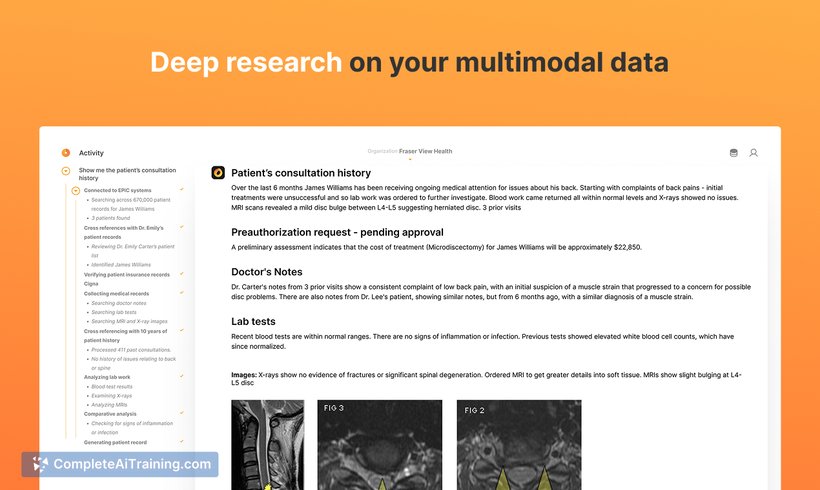
About SmolVLM2
SmolVLM2 is an AI tool designed for visual-language modeling, enabling users to perform tasks that involve understanding and generating content based on both images and text. It offers a compact and efficient approach to multimodal AI applications, making it suitable for various use cases where resource constraints are a consideration.
Review
SmolVLM2 presents a practical solution for those seeking a lightweight yet capable visual-language model. It balances performance and efficiency, making it accessible for developers and researchers who require multimodal AI without the need for extensive computational resources. The tool’s design focuses on delivering relevant outputs across diverse tasks involving image and text data.
Key Features
- Compact model architecture optimized for lower resource consumption
- Supports various multimodal tasks including image captioning and visual question answering
- Effective integration of visual and textual information for improved context understanding
- Pretrained on diverse datasets to enhance generalization capabilities
- Open-source availability facilitating customization and further development
Pricing and Value
SmolVLM2 is available as an open-source model, which means there are no direct costs associated with accessing or using the tool. This makes it a valuable option for individuals and organizations looking to experiment or implement visual-language capabilities without financial barriers. However, users should consider the infrastructure costs for running the model depending on their deployment scale.
Pros
- Lightweight design allows deployment on machines with limited hardware
- Open-source nature encourages community support and enhancements
- Versatile for multiple multimodal AI tasks
- Good performance given its size and efficiency
- Relatively easy to integrate within existing AI workflows
Cons
- May not match the accuracy of larger, more resource-intensive models
- Limited documentation could challenge new users during setup
- Performance can vary depending on the complexity of the input data
SmolVLM2 is well suited for developers and researchers who need an efficient visual-language model that balances capability with resource use. It works best in scenarios where computational efficiency is important, such as edge devices or smaller-scale projects, while still providing meaningful outputs for multimodal tasks.
Open 'SmolVLM2' Website
Your membership also unlocks: