About Tokenwise
Tokenwise is a one-line LLM proxy (OpenAI-compatible baseURL) aimed at makers and small teams who want visibility into API spend. It inspects real requests, calculates exact token costs, and highlights where money is being wasted while offering fixes you can apply directly.
Review
Tokenwise focuses on cost observability and actionable optimization for LLM usage, combining per-request billing insight with automated recommendations. The tool emphasizes verifying any change against your own traffic and provides a low-friction integration path to see savings in actual dollars.
Key Features
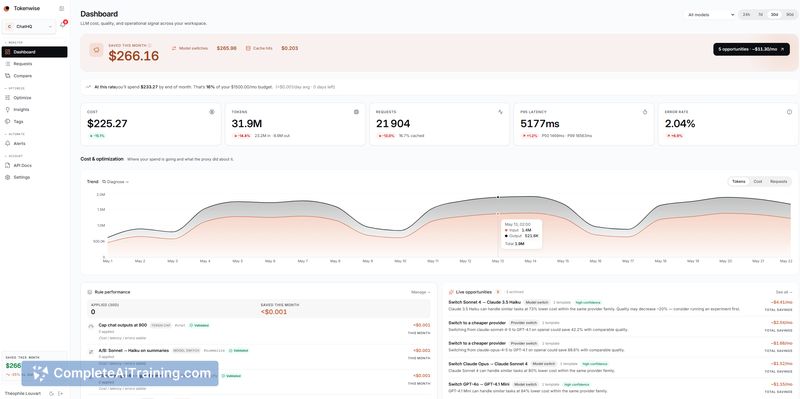
- One-line LLM proxy that captures every request: cost, input/output token counts, latency, status, and error types.
- Exact cost calculation by re-tokenizing requests against current pricing tables so reported numbers match invoices more closely.
- Quality checks and simulated rewrites on your own traffic, with A/B rollout for any applied change to monitor quality, latency, and cost impact.
- Semantic clustering of prompt templates and recommendations for fixes (cheaper model, caching, prompt trimming) with a tracked "saved this month" metric.
- Edge deployment with minimal latency overhead (typically ~30-50ms p50) and optional full payload logging per project for debugging or audits.
Pricing and Value
Tokenwise offers a free-to-start option with no card required, making it accessible for prototypes and early apps. There are paid plans (early users are offered promotional discounts such as 50% off) that scale with usage and the value comes from concrete dollar savings rather than just charts: recommendations can be applied and verified on live traffic so you can measure actual bill reduction before committing.
Pros
- Extremely simple integration path: one-line proxy or point agents at the baseURL with no production changes required.
- Accurate cost attribution by re-tokenizing requests, which helps reconcile engineering intuition with invoice line items.
- Actionable recommendations plus safety: A/B rollout and quality checks reduce the risk of degrading output when applying optimizations.
- Low runtime overhead due to edge execution, and fine-grained request metadata (model, provider, tags) for targeted optimizations.
- Free entry tier lowers the barrier to try it and discover hidden waste early in a project's lifecycle.
Cons
- Still an early product, so some advanced views (for example, native session grouping without custom tags) are on the roadmap rather than available today.
- Full-text prompt/response capture is opt-in for privacy, which means deeper analysis requires opting into additional telemetry.
- Applying automated fixes requires trust in the recommendations; while A/B testing helps, teams may want more granular controls or manual review for critical flows.
Tokenwise is best suited for makers and small engineering teams who want to stop guessing about where API spend goes and start measuring real savings quickly. It scales to heavier users who will see larger absolute savings, and it's a practical tool for anyone who prefers concrete, testable changes over dashboards alone.
Open 'Tokenwise' Website
Your membership also unlocks: