
Video Course: Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer
Master Retrieval Augmented Generation (RAG) and elevate your AI expertise. Learn to integrate private data with Large Language Models through hands-on examples and advanced techniques.
Related Certification: Certification: Build RAG Applications with Python and LangChain for AI Solutions
Also includes Access to All:
What You Will Learn
- Master the RAG pipeline: indexing, retrieval, generation
- Build embeddings and vector-store indexes for efficient search
- Apply query translation, decomposition, and RAG fusion techniques
- Design, monitor, and debug RAG flows with LangChain, LangGraph, and LangSmith
Study Guide
Introduction
Welcome to the comprehensive video course on Retrieval Augmented Generation (RAG). This course is designed to take you from the fundamentals to advanced concepts, equipping you with the skills to effectively leverage RAG in conjunction with Large Language Models (LLMs). In the era where data is a critical asset, understanding how to integrate private data with the capabilities of LLMs is invaluable. Whether you're a developer, data scientist, or a tech enthusiast, this course will deepen your understanding of RAG and its practical applications.
Motivation and Fundamentals of RAG
The motivation behind RAG is clear: while LLMs are trained on publicly available datasets, a significant portion of data is private. RAG bridges this gap by allowing LLMs to access and process information from private sources, enhancing their utility and accuracy.
Example:
Imagine a healthcare organization that wants to use an LLM to provide medical advice. The LLM, trained on public medical literature, might lack access to private patient records. RAG enables the integration of these records, allowing the LLM to offer personalized insights.
Another fundamental aspect of RAG is leveraging expanding context windows. As context windows grow, LLMs can ingest larger volumes of data, making it feasible to feed them significant amounts of private data.
Example:
Consider a legal firm using an LLM for case analysis. With larger context windows, the LLM can process entire case files, offering comprehensive legal advice based on both public laws and private case histories.
RAG Definition and Core Steps
RAG involves three core steps: Indexing, Retrieval, and Generation.
Indexing: This involves processing and structuring external data for efficient retrieval. Data is often stored in databases or vector stores.
Example:
A news agency might index its articles in a vector store, allowing for quick retrieval of relevant articles based on a user's query.
Retrieval: This step identifies and fetches relevant indexed documents based on an input query, using similarity heuristics.
Example:
A search engine retrieves the most relevant web pages for a user's search query by comparing the query's vector with those of indexed pages.
Generation: The retrieved documents, along with the original query, are passed to an LLM, which generates an answer grounded in the provided context.
Example:
A customer support bot retrieves previous customer interactions and uses them to generate a contextually relevant response to a new customer query.
Advanced RAG Techniques (Query Translation)
Advanced techniques in RAG focus on optimizing the retrieval process through query translation.
Query Rewriting/Transformation: This involves modifying the user's question to enhance retrieval.
Example:
A user asks, "How to improve battery life?" The system might rewrite it to "Tips for extending smartphone battery life" for better search results.
Query Decomposition: Breaking down complex questions into simpler sub-questions.
Example:
A complex query like "What are the economic impacts of climate change on agriculture?" can be decomposed into "What is the economic impact of climate change?" and "How does climate change affect agriculture?"
Multi-Query: Generating multiple variations of the original question to increase recall.
Example:
For the query "Best practices for remote work," variations like "Remote work productivity tips" and "How to work effectively from home" can be used to retrieve diverse perspectives.
RAG Fusion: Incorporating a reciprocal rank fusion step to intelligently rank retrieved documents from multiple queries.
Example:
When searching for "sustainable energy solutions," RAG Fusion might rank results from queries like "renewable energy technologies" and "green energy initiatives."
Step-Back Prompting: Asking a more abstract question as a precursor to answering the user's specific query.
Example:
Before answering "How to reduce carbon footprint?" a system might first retrieve information on "What is carbon footprint?"
Routing
Routing directs the potentially translated question to the most appropriate data source based on the question's content.
Logical Routing: Uses an LLM's reasoning capabilities to determine the best source.
Example:
A financial advisor bot directs investment-related queries to a financial database and tax-related queries to a tax database.
Semantic Routing: Embedding the question and comparing its similarity to embeddings of prompts associated with different data sources.
Example:
A travel assistant system might route a query about "best hotels in Paris" to a hospitality database based on semantic similarity.
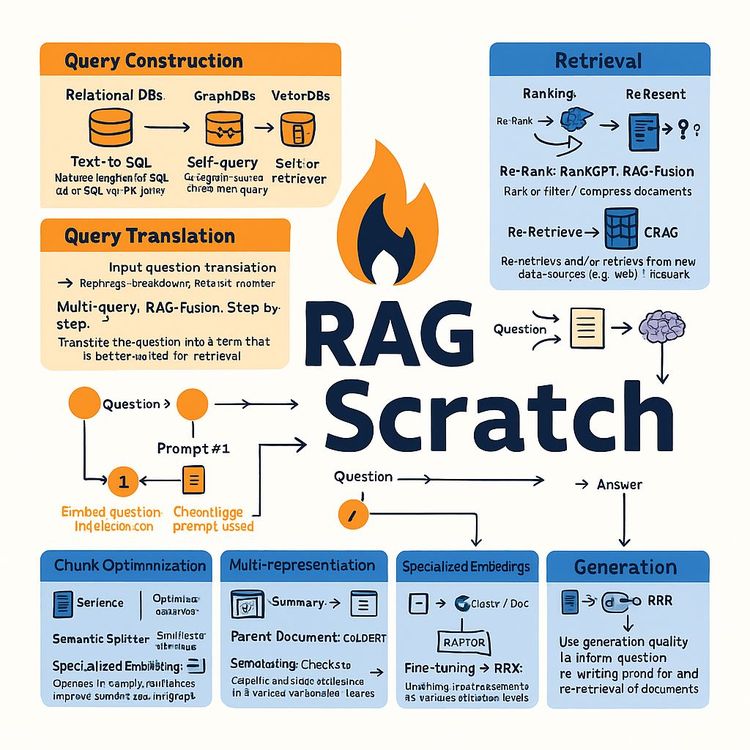
Query Construction
Converting natural language questions into the specific query language required by the target data source.
Example:
A user asks, "Show me sales data for Q1." The system constructs a SQL query: "SELECT * FROM sales WHERE quarter = 'Q1'."
Example:
For a graph database, a query like "Find connections between Person A and Person B" might be translated into a Cypher query.
Indexing Strategies
Indexing strategies are crucial for efficient retrieval in RAG systems.
Loading and Splitting Documents: Raw documents are loaded and split into smaller chunks due to context window limitations.
Example:
A book is split into chapters or sections to fit within the LLM's context window.
Embedding Documents: These chunks are converted into numerical vector representations that capture their semantic meaning.
Example:
An article on climate change is embedded into vectors representing its key themes and ideas.
Vector Stores: These embeddings, along with references to the original document splits, are stored in vector databases for efficient similarity search.
Example:
A vector store of scientific papers allows quick retrieval of research relevant to a specific query.
Multi-Representation Indexing: Decoupling the unit for retrieval from the raw document.
Example:
A summary of a legal document is indexed for retrieval, while the full document is stored separately for detailed analysis.
Hierarchical Indexing (Raptor): Building a hierarchical index of document summaries for better retrieval.
Example:
A company might use hierarchical indexing to organize and retrieve internal reports at different levels of detail.
Token-Level Similarity (Coarse-to-Fine Ranking - ColBERT): Computes similarity at the token level between the question and the document.
Example:
A search system uses token-level similarity to improve the accuracy of retrieving relevant legal cases.
Retrieval and Ranking
Retrieval involves embedding the question and performing a similarity search to find relevant documents.
Similarity Search: Uses techniques like k-Nearest Neighbors (KNN) to find the most relevant document embeddings.
Example:
A recommendation system retrieves similar products based on customer queries using KNN.
Retrieval Parameter (K): Determines the number of nearest neighbors to retrieve.
Example:
Setting K to 5 might retrieve the top 5 most relevant documents for a given query.
Re-ranking and Filtering: Techniques applied to re-rank or filter retrieved documents based on various criteria.
Example:
A system might re-rank search results based on user feedback or relevance scores.
Generation
Generation involves using the retrieved documents in the LLM's context window to generate an informed answer.
Prompting with Context: The retrieved documents are "stuffed" into the LLM's context window along with the original question.
Example:
A chatbot uses customer history and the current query to generate a personalized response.
LangChain Expression Language (LCEL): Provides a language for composing prompts, LLMs, parsers, retrievers, and other components into chains.
Example:
Using LCEL, a developer creates a chain that retrieves data, processes it, and generates a response in a single flow.
Active RAG: The LLM actively decides when and where to retrieve based on the context of the question.
Example:
An LLM might decide to perform additional retrieval if the initial results are deemed insufficient for generating a complete answer.
Corrective RAG: Retrieved documents are graded for relevance, and alternative retrieval strategies are employed if necessary.
Example:
If a retrieved document is not relevant, the system might perform a web search to find more suitable information.
Routing to External Sources (Web Search)
Web search can be integrated into RAG pipelines as an alternative or supplementary data source.
Example:
A virtual assistant uses web search to find the latest news articles when private data sources are insufficient.
Example:
Query rewriting optimizes queries for web search, enhancing the retrieval of relevant information.
Evaluation and Monitoring (LangSmith)
Tools like LangSmith are crucial for tracing, observing, debugging, and evaluating RAG pipelines.
Example:
A developer uses LangSmith to trace the flow of information and identify bottlenecks in the RAG pipeline.
Example:
LangSmith enables the inspection of intermediate steps, such as generated sub-questions and retrieved documents, to improve system performance.
The Evolving Role of RAG in the Age of Long Context LLMs
As LLMs' context windows increase, the role of RAG is evolving rather than becoming obsolete.
Example:
While LLMs can process more data directly, RAG remains essential for retrieving specific, verifiable documents.
Example:
Future RAG systems may emphasize retrieving full documents and incorporate more sophisticated reasoning steps.
Flow Engineering with LangGraph: LangGraph provides a framework for building more complex and stateful RAG flows.
Example:
A developer uses LangGraph to create a RAG system with conditional logic and feedback loops, enhancing adaptability.
Agentic RAG: LangGraph enables the creation of RAG systems with "agentic properties," where the LLM can decide on the next steps.
Example:
An agentic RAG system might autonomously decide to perform additional retrieval based on the quality of intermediate results.
Conclusion
By completing this course, you have gained a comprehensive understanding of Retrieval Augmented Generation (RAG) and its integration with Large Language Models (LLMs). You are now equipped to apply these techniques thoughtfully, enhancing the capabilities of LLMs with private data. Whether you're developing advanced AI applications or optimizing existing systems, the skills acquired here will be instrumental in your journey. Remember, the thoughtful application of RAG can unlock new possibilities in data-driven decision-making and personalized user experiences.
Podcast
There'll soon be a podcast available for this course.
Frequently Asked Questions
Welcome to the comprehensive FAQ section for the 'Video Course: Learn RAG From Scratch – Python AI Tutorial from a LangChain Engineer'. This resource is designed to answer your questions about Retrieval Augmented Generation (RAG) and its integration with Large Language Models (LLMs). Whether you're a beginner or an advanced practitioner, you'll find valuable insights and practical guidance here.
What is Retrieval Augmented Generation (RAG) and why is it important?
RAG, or Retrieval Augmented Generation, enhances Large Language Models (LLMs) by allowing them to access and incorporate information from external, often private, data sources during their response generation process. This is crucial because most of the world's data is not publicly available and therefore not part of the LLMs' original training sets. By feeding relevant external data into an LLM's context window, RAG enables these models to provide more accurate, up-to-date, and contextually appropriate answers grounded in specific knowledge bases.
How does the basic RAG process work?
The fundamental RAG pipeline involves three main steps: indexing, retrieval, and generation. First, the external data sources (e.g., documents, databases) are processed and indexed, often by creating vector embeddings which are numerical representations of the text's semantic meaning. This allows for efficient searching based on similarity. Second, when a user poses a question, that question is also embedded, and a retrieval mechanism (like a vector store similarity search) identifies the most relevant indexed documents or chunks of data. Finally, these retrieved pieces of information are passed to an LLM along with the original question. The LLM then uses this augmented context to generate an answer that is informed and grounded by the retrieved data.
What is "query translation" in the context of RAG?
Query translation refers to techniques used to modify or rewrite a user's initial question to improve the effectiveness of the retrieval step. The goal is to create a query that is better suited for matching against the indexed data. This can involve various methods such as query rewriting, decomposing the query into sub-questions, or even stepping back to ask a more abstract question to retrieve broader contextual information. Techniques like multi-query and RAG Fusion fall under this umbrella, aiming to capture different perspectives of the original question to enhance the likelihood of retrieving relevant documents.
Why might "routing" be necessary in a RAG system?
Routing directs a user's question to the most appropriate data source(s) based on the content or nature of the query. In sophisticated RAG implementations, multiple data sources, such as different vector stores or databases, may be available. Routing can be achieved through logical routing, where an LLM uses its understanding of the data sources to decide, or semantic routing, where embeddings of the question are compared to embeddings of prompts associated with each data source to determine the best match.
How does "query construction" enhance RAG beyond simple keyword search?
Query construction transforms a natural language question into a more structured query that can leverage the specific capabilities of the underlying data source. For vector stores, this might involve constructing metadata filters based on entities or attributes mentioned in the question, allowing for a more precise search. This allows for more targeted and effective retrieval than just relying on the semantic similarity between embeddings.
What are some advanced indexing techniques used in RAG?
Advanced indexing techniques aim to optimise retrieval. Multi-representation indexing involves creating multiple representations of a document, like a summary and the full text, indexing the summary for efficient retrieval, and using the summary to fetch the full document for generation. Hierarchical indexing, like that used in Raptor, involves creating multiple levels of summaries by clustering and summarising documents recursively. Another technique, ColBERT, uses a late interaction approach to compute document-query similarity, potentially offering improved accuracy.
What is "active RAG" and how does LangGraph facilitate its implementation?
Active RAG involves the LLM actively deciding when and how to perform retrieval and refining the retrieval process based on initial results or generated output. LangGraph is a framework that allows developers to build sophisticated, multi-step RAG flows as state machines represented by graphs. This enables the creation of complex logical flows with conditional edges, allowing the system to adapt its behaviour based on the outcomes of different stages in the pipeline.
How might the increasing context window sizes of LLMs impact the future of RAG?
Larger context windows allow LLMs to process more information at once, but RAG remains relevant. Even with the ability to ingest large amounts of data, challenges remain in precisely retrieving multiple relevant facts and reasoning over them effectively. The future of RAG is likely to shift towards more sophisticated techniques that leverage longer contexts for processing full documents, employing advanced indexing methods for document-level retrieval, and incorporating reasoning and feedback loops to improve the quality and reliability of generated answers.
What is the core motivation behind using RAG with LLMs?
The primary motivation for RAG is that most of the world's data is private, whereas LLMs are trained on publicly available data. RAG bridges this gap by allowing LLMs to access and process information from external, private sources that were not part of their original training. This enhances the model's ability to provide accurate and contextually relevant responses.
What is the purpose of "indexing" in the context of RAG?
Indexing organises and structures data for efficient retrieval based on content. Indexed data can take various forms, such as relational databases, vector stores containing document embeddings, or graph databases. This process is crucial for enabling effective retrieval and generating contextually informed responses.
Explain the concept of "embedding" documents and queries in RAG.
Embedding converts text documents and user queries into numerical vector representations that capture their semantic meaning. This allows for easy comparison and similarity searching between documents and queries, which is crucial for effective retrieval. Embedding ensures that the most relevant information is identified and used in generating responses.
Describe how "retrieval" works in a vector store using semantic similarity.
Retrieval in a vector store involves embedding the user's query into the same high-dimensional space as the document embeddings. A similarity search, such as k-nearest neighbours (KNN), is performed to find the document embeddings closest to the query embedding, indicating semantic similarity. This process ensures that the most relevant documents are retrieved for generating an informed answer.
What is the role of a "prompt" in the generation phase of RAG?
A prompt in RAG generation acts as a template that instructs the LLM on how to use the retrieved documents to answer the user's question. Key variables in a RAG prompt typically include placeholders for the retrieved "context" (documents) and the user's "question". This structured input helps guide the model in generating a coherent and contextually grounded response.
What is "multi-representation indexing" and how does it differ from directly indexing document splits?
Multi-representation indexing involves creating multiple representations of a document for indexing and retrieval. A common approach is to generate a concise summary or proposition of the document and index that, while the full document is stored separately. This allows for efficient retrieval based on the summary, followed by the LLM processing the complete document for generation, offering a more nuanced and efficient retrieval process.
How does active RAG enhance the traditional RAG pipeline?
Active RAG incorporates feedback loops and decision-making within the RAG pipeline. This includes steps like grading retrieved documents for relevance, checking generated answers for faithfulness, and using these evaluations to trigger actions like re-retrieval with a rewritten query or regeneration of the answer. This dynamic approach enhances the performance and reliability of RAG systems.
What challenges do LLMs face that RAG helps address?
LLMs often lack access to up-to-date and proprietary information, as they are typically trained on publicly available data. RAG helps address this by allowing LLMs to retrieve and incorporate information from external sources, ensuring responses are more accurate and relevant to specific queries. This capability is particularly valuable in business environments where proprietary data is crucial.
How can RAG be practically applied in business settings?
RAG can be used to enhance customer support, research, and decision-making in business settings. For example, a customer support chatbot can use RAG to access a company's extensive product documentation, providing accurate and timely responses to customer queries. Similarly, RAG can assist in research by retrieving relevant academic papers or proprietary reports to inform strategic decisions.
What are some common misconceptions about RAG?
A common misconception is that RAG is only useful for large-scale data retrieval. In reality, RAG is valuable for both small and large data sets. Its ability to access specific, contextually relevant information makes it a versatile tool for various applications, regardless of the data volume. Additionally, some may assume RAG replaces traditional search methods, but it often complements them by providing more nuanced and context-aware results.
How does RAG differ from traditional search methods?
RAG differs from traditional search methods by integrating retrieved data into the response generation process. Traditional search typically retrieves and presents information separately, while RAG uses the retrieved data as context for generating more informed and relevant responses. This integration allows RAG to provide nuanced answers that reflect the specific needs and context of the user's query.
What are the potential challenges in implementing RAG systems?
Implementing RAG systems can involve challenges related to data integration and model tuning. Ensuring that the system accurately retrieves and uses relevant data requires careful indexing and embedding strategies. Additionally, tuning the LLM to effectively utilise the augmented context can be complex. Addressing these challenges requires a deep understanding of both the RAG framework and the specific data sources involved.
What is the future of RAG in AI development?
The future of RAG involves more sophisticated integration with LLMs, leveraging longer context windows and advanced indexing techniques. As LLMs continue to evolve, RAG will play a crucial role in ensuring these models can access and utilise external data effectively. This will enhance the accuracy and relevance of AI-generated responses, making RAG an integral component of advanced AI systems.
Can small businesses benefit from using RAG?
Yes, small businesses can benefit from using RAG to improve customer interactions and streamline information retrieval processes. By integrating RAG into their systems, small businesses can enhance their ability to provide accurate and timely responses to customer inquiries, leveraging their own proprietary data to gain a competitive edge. This can lead to improved customer satisfaction and more efficient operations.
How does RAG handle data privacy concerns?
RAG systems can be designed to respect data privacy by securely integrating proprietary data without exposing it to external entities. By keeping data retrieval and processing within secure environments, businesses can ensure that sensitive information is protected. Additionally, implementing robust access controls and encryption can further safeguard data privacy in RAG applications.
How is RAG driving innovation in AI applications?
RAG is driving innovation by enabling AI systems to provide more contextually relevant and accurate responses. By integrating external data sources, RAG enhances the capabilities of LLMs, allowing them to address complex queries with greater precision. This innovation is particularly impactful in fields such as healthcare, finance, and customer service, where access to specific, up-to-date information is critical.
Certification
About the Certification
Show the world you have AI skills—master Retrieval Augmented Generation (RAG) with Python and LangChain. Gain hands-on experience designing advanced AI solutions and add an in-demand credential to your professional profile.
Official Certification
Upon successful completion of the "Certification: Build RAG Applications with Python and LangChain for AI Solutions", you will receive a verifiable digital certificate. This certificate demonstrates your expertise in the subject matter covered in this course.
Benefits of Certification
- Enhance your professional credibility and stand out in the job market.
- Validate your skills and knowledge in cutting-edge AI technologies.
- Unlock new career opportunities in the rapidly growing AI field.
- Share your achievement on your resume, LinkedIn, and other professional platforms.
How to complete your certification successfully?
To earn your certification, you’ll need to complete all video lessons, study the guide carefully, and review the FAQ. After that, you’ll be prepared to pass the certification requirements.
Other AI Video Courses

Video Course: What is Generative AI and how does it work?

Video Course: How to Use ChatGPT from Beginner to Professional

Video Course: How to Use Google Gemini for Google Workspace to Boost Productivity

Video Course: How to Use Claude 3.7 AI - Tips for Beginners!

Video Course: ChatGPT for Data Analytics: Full Course - from Beginners to Professional

Video Course: Generating Images and photos With ChatGPT?

Video Course: Generating Images & Photo's with MidJourney

Video Course: Generating Design's with Microsoft Designer and AI

Video Course: Generating Design's with Canva.com and AI
Join 20,000+ Professionals, Using AI to transform their Careers
Join professionals who didn’t just adapt, they thrived. You can too, with AI training designed for your job.







