
Video Course: RAG Fundamentals and Advanced Techniques – Full Course
Dive into the world of Retrieval Augmented Generation (RAG) and master techniques that enhance Large Language Models with cutting-edge data integration.
Related Certification: Certification: RAG Fundamentals & Advanced Techniques for Applied AI Solutions
Also includes Access to All:
What You Will Learn
- Understand RAG principles and core components
- Build an end-to-end naive RAG pipeline (chunking, embeddings, ChromaDB)
- Identify limitations and common pitfalls of naive RAG
- Implement advanced techniques (query expansion, multi-query retrieval, reranking)
- Deploy and optimise RAG systems for real-world use
Study Guide
Introduction
Welcome to the comprehensive guide on Retrieval Augmented Generation (RAG), a cutting-edge technique designed to enhance the capabilities of Large Language Models (LLMs) by integrating external data sources. This course, "Video Course: RAG Fundamentals and Advanced Techniques – Full Course", aims to provide you with a thorough understanding of RAG, from its fundamental principles to advanced techniques that address the limitations of naive implementations. Whether you're a software engineer, data scientist, or AI enthusiast, this guide will equip you with the knowledge and skills to implement RAG effectively in various applications.
Understanding the Fundamentals of RAG
Definition: At its core, RAG is a framework that combines retrieval-based systems with generation-based models to produce more accurate and contextually relevant responses. By leveraging both retrieval and generation, RAG aims to overcome the limitations of LLMs, which are often constrained by their training data.
For instance, consider an LLM like ChatGPT. It can generate coherent text based on its training data but lacks access to specific or up-to-date information. RAG solves this by allowing users to "inject" their own data into the LLM's process, ensuring that responses are grounded in the most relevant and current information.
Core Components of RAG
RAG consists of several key components that work in tandem:
- Retriever: This component identifies and retrieves relevant documents based on the user's query.
- Generator: The generator takes the retrieved documents and the input query to generate a coherent and contextually relevant response.
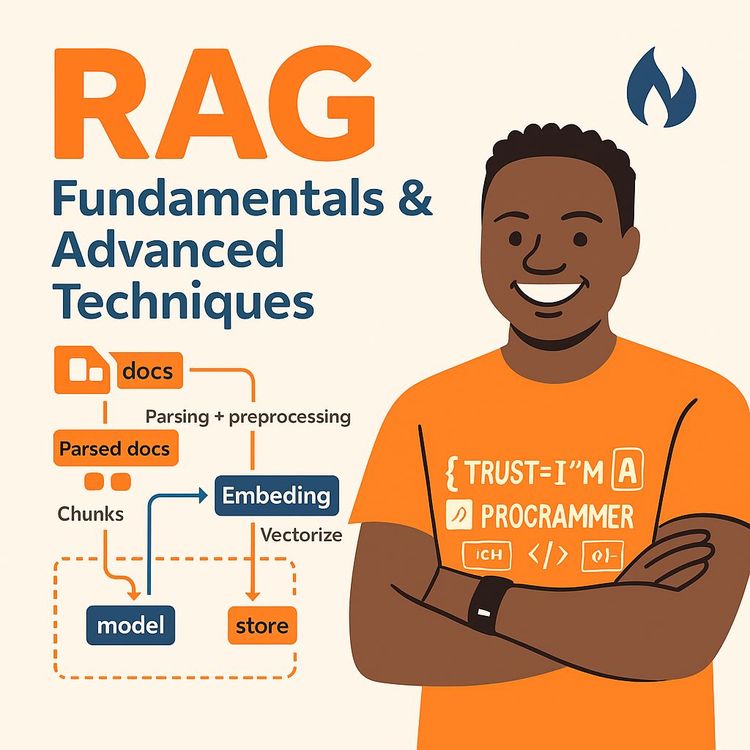
In a typical RAG workflow, documents are pre-processed and indexed. This involves parsing documents, cleaning them, and splitting them into smaller chunks. These chunks are then transformed into vector representations (embeddings) using an embedding model, such as OpenAI's embedding models. The embeddings are stored in a vector database like ChromaDB.
Naive RAG Workflow
The naive RAG workflow involves several steps:
- Indexing: Documents are parsed and pre-processed, then split into smaller chunks. These chunks are embedded and stored in a vector database.
- Retrieval: The user's query is embedded and used to search the vector database for the most similar document embeddings. Relevant document chunks are retrieved.
- Augmentation: The original query is combined with the retrieved document chunks to form an augmented prompt.
- Generation: The augmented prompt is passed to an LLM, which generates a response using the provided context.
For example, if a user queries about the impact of AI on TV writers, the system retrieves relevant news articles and augments the query with this information before generating a response.
Practical Implementation of Naive RAG
To implement a basic RAG system, you'll need a Python setup, VS Code, and an OpenAI account with an API key. The course demonstrates building a RAG system using libraries like python-dotenv, openai, and chromadb.
Here are the steps involved:
- Load documents (e.g., .txt files from a directory).
- Split documents into smaller chunks for better relevance and to fit within model context windows.
- Create embeddings for each chunk using OpenAI's embedding model.
- Save the chunks and their embeddings into a ChromaDB vector store.
- Create a function to query the vector database by embedding the user's query and performing a similarity search.
- Create a function to generate a response by taking the user's query and the retrieved relevant document chunks and prompting the LLM.
For instance, querying news articles about AI replacing TV writers and DataBricks demonstrates the practical application of these steps.
Limitations and Pitfalls of Naive RAG
While naive RAG offers significant benefits, it also faces several challenges:
- Limited Contextual Understanding: Naive RAG might struggle with queries requiring understanding relationships between concepts discussed in different documents. For example, a query about the impact of climate change on polar bears might retrieve separate documents about climate change and polar bears without connecting them effectively.
- Inconsistent Relevance and Quality of Retrieved Documents: The relevance and quality of retrieved documents can vary, leading to poor inputs for the generative model. For instance, a query about the latest AI ethics research might retrieve outdated or less credible sources.
- Poor Integration Between Retrieval and Generation: The retriever and generator often operate independently, leading to suboptimal performance. The generator might ignore crucial context from retrieved documents. For example, the LLM might generate a generic answer despite relevant context being retrieved.
- Inefficient Handling of Large-Scale Data: Naive RAG can struggle with large datasets due to inefficient retrieval mechanisms, leading to slower response times.
- Lack of Robustness and Adaptability: Naive RAG might not handle ambiguous or complex queries well and may not adapt to changing contexts without manual intervention. For example, a vague query about "index funds and anything related to finances" might not yield a coherent answer.
Advanced RAG Techniques and Solutions
Advanced RAG techniques aim to overcome the limitations of naive RAG by introducing improvements in pre-retrieval and post-retrieval stages. These techniques include:
Query Expansion with Generated Answers
This technique involves using the LLM to generate a potential answer to the initial query. The generated answer is concatenated with the original query to form a new, expanded query. This expanded query is used to retrieve more relevant documents from the vector database.
For example, if the original query is "impact of AI on creative jobs," the LLM might generate an answer that includes terms like "AI replacing writers" or "future of music composition with AI." These terms are then used to retrieve documents that are more semantically related to the query.
Benefits: This approach can capture semantically related documents that might not match the original query terms directly.
Query Expansion with Multiple Queries
In this technique, the LLM generates multiple relevant or related subqueries based on the original query. Each subquery is used to retrieve documents from the vector database. The retrieved documents from all subqueries are combined and used to generate a more comprehensive and contextually relevant final answer.
For example, a query like "impact of AI on creative jobs" might lead to subqueries such as "AI replacing writers," "AI art generation trends," and "future of music composition with AI." Each subquery retrieves different sets of documents, which are then combined to provide a more comprehensive answer.
Benefits: This technique can explore different aspects and interpretations of the original query, leading to a more diverse and comprehensive set of relevant documents.
Next Steps
The course suggests further exploration of advanced techniques to address the issue of noise in search results, likely involving document ranking and feedback mechanisms. These techniques will further enhance the relevance and quality of retrieved documents, improving the overall performance of RAG systems.
Conclusion
By now, you should have a comprehensive understanding of Retrieval Augmented Generation (RAG), from its basic principles to advanced techniques. RAG offers a powerful way to augment LLMs with external data, ensuring more accurate and contextually relevant responses. As you apply these skills, remember the importance of thoughtful implementation and continuous improvement. The potential of RAG is vast, and with the knowledge gained from this course, you're well-equipped to harness its capabilities in your projects and applications.
Podcast
There'll soon be a podcast available for this course.
Frequently Asked Questions
Welcome to the FAQ section for the 'Video Course: RAG Fundamentals and Advanced Techniques – Full Course.' This resource is designed to answer your questions about Retrieval Augmented Generation (RAG), a powerful framework that enhances large language models by integrating external data sources. Whether you're new to RAG or looking to deepen your understanding, this FAQ covers everything from basic concepts to advanced techniques and implementation challenges.
What is Retrieval Augmented Generation (RAG) and how does it work?
Retrieval Augmented Generation (RAG) is a framework that enhances the capabilities of large language models (LLMs) by allowing them to access and incorporate information from external knowledge sources when generating responses. Traditional LLMs are trained on vast amounts of data up to a certain point in time, meaning they lack awareness of more recent information or specific private data. RAG addresses this limitation by first retrieving relevant documents or data based on a user's query and then augmenting the LLM's input with this retrieved information. This allows the LLM to generate more accurate, contextual, and up-to-date answers, as it's grounding its response in the provided external knowledge. The process typically involves indexing a knowledge base (e.g., documents, databases) by creating vector embeddings of the content. When a user asks a question, the query is also embedded, and a similarity search is performed in the vector database to retrieve the most relevant chunks of information. These retrieved chunks, along with the original query, are then fed into the LLM, which uses this augmented context to generate its response.
Why is RAG necessary when we already have powerful Large Language Models?
While LLMs are powerful in their ability to understand and generate human-like text, they have inherent limitations. They are trained on a fixed dataset, which means their knowledge is confined to what they were trained on and can become outdated. They also lack access to private or domain-specific data that an organisation might possess. Furthermore, LLMs can sometimes generate plausible-sounding but incorrect information, a phenomenon known as hallucination, especially when they are asked about topics outside their training data. RAG mitigates these issues by providing the LLM with a reliable source of information relevant to the user's query. This ensures that the LLM's responses are more grounded in factual data, up-to-date, and can incorporate specific knowledge that the LLM was not originally trained on, reducing the risk of hallucination and increasing accuracy.
What are the key components of a RAG system?
A typical RAG system consists of several key components working together:
- Knowledge Base/Data Source: This is the collection of documents, databases, or other unstructured data that the RAG system will use to retrieve relevant information.
- Indexing Process: This involves parsing the data source, splitting it into smaller chunks (chunking), and then creating vector embeddings of these chunks using an embedding model (often an LLM or a dedicated embedding model). These embeddings capture the semantic meaning of the text and are stored in a vector database.
- Vector Database/Vector Store: This is a specialised database designed to efficiently store and search high-dimensional vector embeddings. It allows for fast retrieval of semantically similar chunks based on a query embedding.
- Retrieval Component (Retriever): This component takes the user's query, converts it into a vector embedding using the same embedding model as the indexing process, and then performs a similarity search in the vector database to identify and retrieve the most relevant chunks of information.
- Augmentation Step: This involves combining the original user query with the retrieved relevant information. This augmented context is then passed to the generation component.
- Generation Component (Generator): This is the Large Language Model that takes the augmented input (query + retrieved context) and generates a coherent and contextually relevant response based on the provided information.
What are the advantages of using RAG?
Using RAG offers several significant advantages:
- Enhanced Accuracy and Contextual Relevance: By grounding the LLM's responses in retrieved external knowledge, RAG ensures that the answers are more accurate and directly relevant to the user's query within the context of the provided data.
- Access to Up-to-Date Information: RAG allows LLMs to answer questions based on the latest information available in the knowledge base, overcoming the temporal limitations of their training data.
- Incorporation of Private and Domain-Specific Data: Organisations can use RAG to enable LLMs to answer questions using their internal documents, proprietary data, and domain-specific knowledge that the LLM wouldn't have access to otherwise.
- Reduced Hallucinations: By providing the LLM with factual context, RAG significantly reduces the likelihood of the model generating incorrect or fabricated information.
- Improved Explainability and Traceability: Since the LLM's responses are based on specific retrieved documents, it's possible to trace the source of the information, making the answers more explainable and trustworthy.
- Customisation and Flexibility: RAG systems can be easily customised with different knowledge bases and can be adapted to various applications and domains.
What are the limitations or challenges of "naive" RAG?
While basic or "naive" RAG provides significant benefits, it also faces several challenges:
- Limited Contextual Understanding: Naive RAG might struggle with queries requiring understanding of relationships or context across multiple retrieved documents if it simply concatenates them. It may fail to identify the most relevant documents if the keywords don't directly match, even if the semantic meaning is related.
- Inconsistent Relevance and Quality of Retrieved Documents: The relevance and quality of retrieved documents can vary, leading to poor-quality inputs for the LLM and potentially less satisfactory responses. Basic similarity search might retrieve documents that are only partially relevant or even irrelevant.
- Poor Integration Between Retrieval and Generation: In naive RAG, the retriever and generator often operate independently. The generator might not effectively utilise the retrieved information, potentially ignoring crucial context or generating generic answers.
- Inefficient Handling of Large-Scale Data: Basic retrieval mechanisms in naive RAG can become inefficient when dealing with very large knowledge bases, leading to slower response times and potentially missing relevant information due to inadequate indexing or search strategies.
- Lack of Robustness and Adaptability to Complex Queries: Naive RAG models might struggle with ambiguous, multi-faceted, or complex queries, failing to provide coherent and comprehensive answers.
- Retrieval of Misaligned or Irrelevant Chunks: Basic retrieval might select document chunks that, while semantically similar to the query, do not actually contain the specific information needed to answer the question.
- Generative Challenges: Even with retrieved context, the LLM might still face challenges such as hallucination, issues with relevance, toxicity, or bias in its outputs.
What are some advanced techniques to improve RAG systems?
To overcome the limitations of naive RAG, various advanced techniques have been developed, including:
- Query Expansion: Augmenting the original query with synonyms, related terms, or contextually similar phrases (potentially using LLMs to generate these expansions or even hypothetical answers to guide retrieval).
- Multi-Query Retrieval: Generating multiple related queries from the original query to explore different facets of the user's intent and retrieve a broader set of relevant documents.
- Reranking: Employing a more sophisticated model (often another LLM or a cross-encoder) to rerank the initially retrieved documents based on their relevance to the query, bringing the most pertinent information to the top.
- Document Pre-processing and Augmentation: Optimising the chunking strategy, adding metadata to documents, or transforming the document content to improve retrieval accuracy.
- Post-Retrieval Processing: Further refining the retrieved context before passing it to the LLM, such as summarising multiple retrieved chunks or extracting key information.
- Integration of Knowledge Graphs: Using knowledge graphs as an additional retrieval source to capture relationships between entities and provide more structured context.
- Iterative Retrieval and Generation: Allowing the LLM to iteratively refine its retrieval based on intermediate generations, leading to more focused and accurate information gathering.
- Retrieval Feedback and Fine-tuning: Using the quality of the generated answers to provide feedback to the retrieval component and potentially fine-tuning the embedding model or retrieval strategy.
How can query expansion with generated answers improve retrieval in RAG?
Query expansion with generated answers is an advanced RAG technique that aims to improve the relevance of search results by first using an LLM to generate a potential answer (a hallucinated answer based on its general knowledge) to the user's initial query. This generated answer is then combined with the original query to form a new, augmented query. The rationale is that the generated answer might contain related terms or concepts that were not explicitly present in the original query but are semantically relevant to the information being sought. By using this augmented query for retrieval from the vector database, the system can potentially identify and retrieve a broader and more relevant set of documents that might have been missed by a simple keyword or semantic similarity search based on the original query alone. This retrieved information, now more relevant, can then be used by the LLM to generate a more accurate and contextually rich final answer to the user's original question.
How does query expansion with multiple queries work as an advanced RAG technique?
Query expansion with multiple queries involves using an LLM to generate several different but related queries based on the user's initial question. The goal is to capture different aspects or interpretations of the original query, potentially uncovering relevant information that a single query might miss. This is achieved by prompting the LLM to think about the user's intent from various angles and formulate distinct questions that, when searched independently, could yield different sets of relevant documents. For example, a query like "impact of AI on creative jobs" might lead to subqueries such as "AI replacing writers," "AI art generation trends," and "future of music composition with AI." Each of these generated subqueries is then used to retrieve relevant documents from the vector database. The retrieved documents from all the subqueries are then combined, and this broader set of context is provided to the LLM to generate a final, more comprehensive answer that addresses the various facets of the user's original inquiry. This technique helps to overcome the limitations of relying on a single query, which might not be specific enough or might not cover all the nuances of the user's information need.
What is the core purpose of Retrieval Augmented Generation (RAG)?
The core purpose of RAG is to enhance the knowledge and accuracy of large language models by allowing them to retrieve and incorporate information from external data sources when generating responses. This helps overcome the LLM's knowledge cutoff and improves grounding.
Why might a large language model not know the name of your first dog, and how does RAG address this limitation?
An LLM like ChatGPT was trained on a broad dataset that likely did not include personal information such as the name of your first dog. RAG solves this by allowing you to "inject" your own data, enabling the LLM to access and use this specific information to answer relevant questions.
What are the two main components of a RAG system, and what is the primary function of each?
The two main components of a RAG system are the retriever and the generator. The retriever's primary function is to identify and fetch relevant documents or information based on the user's query. The generator, which is the LLM, then uses the retrieved information and the query to produce a response.
Describe the process of indexing documents for use in a RAG system.
Indexing involves several steps: first, documents are parsed and pre-processed, often including being split into smaller chunks. These chunks are then passed through an embedding model to create vector embeddings, which are numerical representations of their semantic meaning. Finally, these embeddings are stored in a vector database for efficient retrieval.
How does the "augmentation" step in RAG contribute to the quality of the generated response?
The augmentation step is crucial because it adds relevant context, retrieved from external sources, to the original user query before it is passed to the large language model. This additional information helps the LLM generate more accurate, contextually relevant, and grounded responses that go beyond its pre-training data.
What is a vector embedding, and why are embeddings important in a RAG system?
A vector embedding is a numerical representation of text in a high-dimensional space, where the position and distance between vectors capture the semantic similarity of the corresponding text. Embeddings are important in RAG because they allow the retrieval system to perform similarity searches in the vector database, finding documents that are semantically related to the user's query.
Explain the concept of "naive RAG" and briefly outline its typical workflow.
Naive RAG is the most basic form of RAG, where documents are simply chunked, embedded, and stored. During a query, the query is also embedded, a similarity search is performed to retrieve relevant chunks, and these chunks are directly concatenated with the prompt for the LLM to generate a response.
Describe one potential pitfall or challenge associated with using naive RAG.
One potential pitfall of naive RAG is limited contextual understanding. The retrieval process might rely heavily on keyword matching or basic semantic similarity, leading to the retrieval of documents that are only partially relevant or miss the broader context of the user's query, especially for complex or nuanced questions.
What is the main goal of employing advanced RAG techniques compared to naive RAG?
The main goal of advanced RAG techniques is to overcome the limitations of naive RAG, such as poor retrieval relevance, limited contextual understanding, and issues with the integration between retrieval and generation. These techniques aim to improve the accuracy, consistency, and overall quality of the RAG system's responses.
Briefly explain the concept of query expansion in the context of advanced RAG.
Query expansion is an advanced RAG technique that aims to improve retrieval by reformulating or adding to the original user query. This can involve generating synonyms, related terms, or even hypothetical answers or multiple related sub-queries to broaden the search and capture a wider range of relevant documents in the vector database.
What are the key advantages of using RAG over relying solely on the internal knowledge of a large language model?
RAG provides several advantages over relying solely on LLMs. It allows for access to up-to-date information by incorporating recent data, improves response accuracy by grounding answers in reliable sources, and enables the use of domain-specific knowledge that an LLM might not have been trained on. Additionally, RAG reduces hallucinations and improves the traceability of responses by linking them to specific documents.
Describe the end-to-end process of building a naive RAG system.
Building a naive RAG system involves several steps: preparing the data by parsing and chunking documents, creating vector embeddings for these chunks, and storing them in a vector database. When a user query is received, it is also embedded, and a similarity search is performed to retrieve relevant chunks. These chunks are then combined with the query and fed into the LLM to generate a response. Each component plays a crucial role in ensuring the system retrieves and uses the most relevant information.
Critically evaluate the limitations and potential pitfalls of naive RAG with examples.
Naive RAG can struggle with complex queries that require understanding across multiple documents, leading to limited contextual understanding. For instance, if a query involves nuanced information that spans several documents, naive RAG might not effectively integrate this context, resulting in incomplete or inaccurate responses. Additionally, the reliance on basic similarity searches can lead to retrieving partially relevant documents, affecting the quality of the generated answer.
How do advanced RAG techniques address the shortcomings of naive RAG?
Advanced RAG techniques, such as query expansion with generated answers or multiple queries, aim to capture a broader range of relevant information by exploring different facets of a user's intent. These techniques enhance retrieval relevance and improve the integration between retrieval and generation. They help overcome limitations by providing more comprehensive context, reducing the likelihood of irrelevant or incomplete responses, and improving overall system performance.
What are the practical steps involved in implementing and deploying a RAG system in a real-world application?
Implementing a RAG system involves several key steps: selecting and preparing a knowledge base, indexing documents by creating vector embeddings, and setting up a vector database for efficient retrieval. The system must be integrated with an LLM for response generation. Key considerations include data management to ensure the knowledge base is up-to-date, scalability to handle large volumes of data, and performance optimisation to ensure fast and accurate responses. Challenges may arise in maintaining data quality and ensuring the system adapts to evolving user needs.
Certification
About the Certification
Show you know how to use AI with expertise in Retrieval-Augmented Generation (RAG). This certification demonstrates your ability to design and implement advanced AI solutions in real-world applications.
Official Certification
Upon successful completion of the "Certification: RAG Fundamentals & Advanced Techniques for Applied AI Solutions", you will receive a verifiable digital certificate. This certificate demonstrates your expertise in the subject matter covered in this course.
Benefits of Certification
- Enhance your professional credibility and stand out in the job market.
- Validate your skills and knowledge in cutting-edge AI technologies.
- Unlock new career opportunities in the rapidly growing AI field.
- Share your achievement on your resume, LinkedIn, and other professional platforms.
How to complete your certification successfully?
To earn your certification, you’ll need to complete all video lessons, study the guide carefully, and review the FAQ. After that, you’ll be prepared to pass the certification requirements.
Other AI Video Courses

Video Course: What is Generative AI and how does it work?

Video Course: How to Use ChatGPT from Beginner to Professional

Video Course: How to Use Google Gemini for Google Workspace to Boost Productivity

Video Course: How to Use Claude 3.7 AI - Tips for Beginners!

Video Course: ChatGPT for Data Analytics: Full Course - from Beginners to Professional

Video Course: Generating Images and photos With ChatGPT?

Video Course: Generating Images & Photo's with MidJourney

Video Course: Generating Design's with Microsoft Designer and AI

Video Course: Generating Design's with Canva.com and AI
Join 20,000+ Professionals, Using AI to transform their Careers
Join professionals who didn’t just adapt, they thrived. You can too, with AI training designed for your job.







