
Building Long-Term Memory for AI Agents with MEMS Zero and Python (Video Course)
Transform your AI agents from forgetful chatbots into truly helpful companions. This hands-on Python course shows you how to build context-aware, persistent memory with MEMS Zero and Qdrant,so your assistants can recall, adapt, and serve users better.
Related Certification: Certification in Implementing Long-Term Memory for AI Agents with Python and MEMS Zero
Also includes Access to All:
What You Will Learn
- Explain LLM context limits and the need for a memory layer
- Implement MEMS Zero's two-phase pipeline in Python
- Configure cloud and self-hosted MEMS Zero with Qdrant
- Tune prompts for fact extraction and memory updates
- Build and test a memory-enabled chat assistant for production
Study Guide
Introduction: Why AI Agents Need Long-Term Memory
Imagine chatting with an assistant that remembers nothing about you after each session,there’s a limit to how useful or “human-like” it can feel.
Long-term memory transforms AI agents from simple chatbots into companions that understand, learn, and adapt to users over time. This course is your complete guide to building these kinds of persistent, context-aware agents using Python and the open-source MEMS Zero framework. We’ll walk step-by-step from foundational concepts, through practical implementation, and into the nuanced art of prompt engineering and framework mastery.
You’ll learn how to:
- Understand the core problem with current AI agent memory
- Harness MEMS Zero’s unique two-phase memory pipeline
- Set up cloud and open-source versions, including persistent storage with vector databases
- Navigate real-world challenges in prompt engineering and framework design
- Apply best practices for robust, production-ready AI systems
The Memory Problem in AI Agents
Why is memory so hard for language models?
Large Language Models (LLMs) like GPT-4o can hold context only within a limited window,usually a few thousand tokens. Once you exceed that, older information drops off. This means that if you want your AI to “remember” your name, preferences, or anything about previous conversations, you need an explicit memory layer.
Example 1: Chatbots That Forget
If you tell a customer service chatbot your address, and later in the conversation it asks again, you notice a lack of continuity. This breaks the illusion of intelligence and quickly leads to frustration.
Example 2: Personal Assistants Without Memory
A virtual assistant that can’t recall your favorite pizza topping or the fact that you have a meeting every Monday at 10am doesn’t feel tailored. It’s just a fancy search engine, not a real assistant.
Beyond Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation is a technique where external documents or databases provide LLMs with extra context. While RAG is powerful for expanding knowledge, it’s not designed for user-specific or experiential memory. It won’t remember that you dislike onions or that you asked for a summary last week.
Takeaway: A dedicated memory layer is essential for human-like, effective AI agents.
Introducing MEMS Zero: The Open-Source Memory Framework
What is MEMS Zero?
MEMS Zero is an open-source framework designed to add persistent memory to AI agents. It stands apart from proprietary or black-box solutions by offering:
- Transparent architecture
- Both cloud and open-source (self-hosted) options
- Lower latency and better performance claims compared to existing solutions
- Token efficiency, making memory affordable at scale
Example 1: Comparing MEMS Zero and ChatGPT Memory
While ChatGPT’s memory is managed by OpenAI and not open to inspection or customization, MEMS Zero gives you control over how memories are stored, updated, and retrieved.
Example 2: MEMS Zero as a Drop-In for Your Own AI Agent
If you’re building a custom assistant, you can use MEMS Zero to plug in long-term memory capabilities, either through its cloud service or by integrating the open-source library with your backend.
Why Open Source? It lets you inspect, understand, and adapt the prompts and mechanisms used for memory management. This is critical as you scale or build for specific use cases.
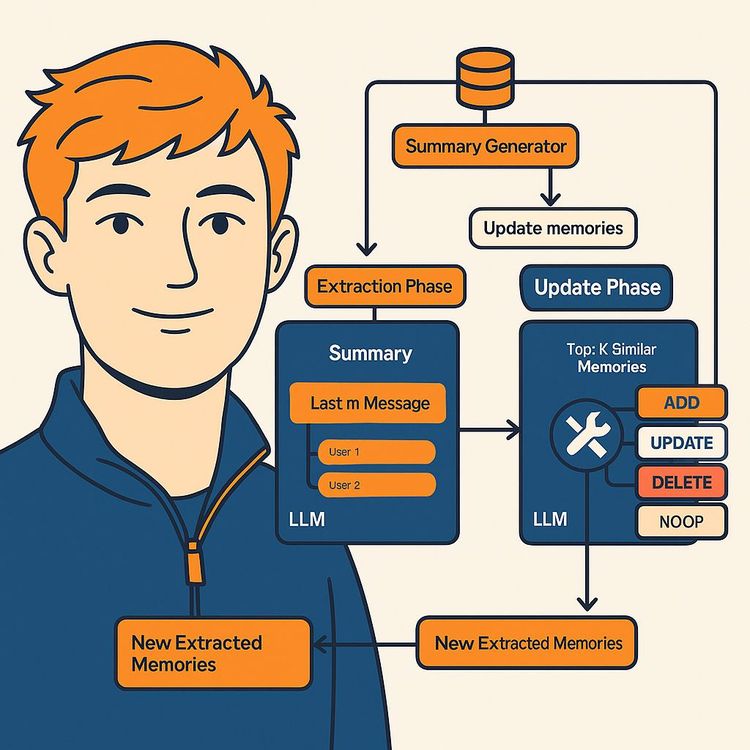
MEMS Zero’s Two-Phase Memory Pipeline: How It Works
The secret sauce of MEMS Zero is its two-phase memory pipeline.
This pipeline is designed to extract, consolidate, and retrieve only the most important facts from conversations. Here’s how it works:
-
Summarization and Fact Extraction
At the end of a conversation (or after each message), an LLM processes the conversation history to create a summary and extract new “memories”,salient facts or events that should be remembered. -
Dynamic Memory Management
A separate LLM uses the extracted facts and summary to decide:- Should these facts be added as new memories?
- Should they update existing memories?
- Should old or outdated memories be deleted?
- Or should nothing change?
Example 1: User Changes a Preference
If a user says, “I love pizza,” the memory layer stores this. Later, if the user says, “Actually, I no longer like pizza,” the dynamic management phase should update or remove the previous memory. MEMS Zero uses LLMs to make this judgment call.
Example 2: New Facts from Conversation
If a user mentions, “I’m traveling to Paris next week,” the system will extract and store this as a new fact, so the agent can follow up or make relevant suggestions in the future.
Key Point: MEMS Zero’s pipeline enables scalable long-term reasoning by keeping only what matters, not every single message.
The Role of LLMs in MEMS Zero Memory Management
LLMs aren’t just for chatting,they power the memory pipeline.
In MEMS Zero, LLMs perform several critical functions:
- Summarizing conversation histories
- Extracting salient facts for storage
- Deciding whether to add, update, delete, or ignore memories
Example 1: Summarization and Fact Extraction
The conversation “User: I have a dog named Max. User: I just adopted a cat named Luna.” is summarized, and the facts (“has a dog named Max”, “adopted a cat named Luna”) are extracted for memory.
Example 2: Dynamic Update Decisions
If a fact contradicts a previous memory (“I sold my car” after “I have a blue car”), the LLM decides to update or remove the old memory so the agent’s knowledge stays current.
Hands-On Tip: The prompts that guide these LLM decisions are open and available in the MEMS Zero GitHub. You can inspect and tailor them for your application.
How MEMS Zero Stores and Retrieves Memories
Memory isn’t just about extraction,it’s about persistence and retrieval.
MEMS Zero supports two main usage patterns:
- Using the cloud platform (app.memszero.ai)
- Using the open-source library in your application
Example 1: Cloud Version (memclient)
You send messages to the cloud API. The background process summarizes, extracts, and stores memories in a vector database. You can then “search” for relevant memories using a query.
Example 2: Open-Source Version (Memory Object)
By default, memories are stored locally and only exist in RAM,they’re lost when the session ends.
Persistent Long-Term Memory with a Vector Database
To achieve true long-term, cross-session memory, you must configure a persistent vector database (like Qdrant). This allows memories to be stored and retrieved across different sessions and devices.
Integrating MEMS Zero with Qdrant for Persistent Memory
What is Qdrant?
Qdrant is an open-source vector database that enables efficient semantic search,critical for retrieving relevant memories based on meaning, not just keywords.
How It Works:
- Configure MEMS Zero to use Qdrant via a configuration file
- Memories (fact embeddings) are stored persistently in Qdrant
- When the agent needs context, it queries Qdrant for relevant memories
- This information is used alongside the current conversation to generate more informed responses
Example 1: Persistent User Preferences
If a user’s preferences are stored in Qdrant, the agent can recall them even after a server restart or across devices.
Example 2: Knowledge Accumulation Over Time
An AI tutor that remembers a student’s strengths and weaknesses across multiple study sessions can offer more personalized guidance.
Best Practice: Always use a persistent database for production agents,RAM-only storage is only for demos or prototyping.
Building an AI Chat Assistant with MEMS Zero and Qdrant: Step-by-Step
Let’s put everything together with a practical workflow.
-
Retrieve Relevant Memories
At the start of each interaction, the assistant queries Qdrant for memories relevant to the current user or session. This primes the LLM with user-specific context. -
Process User Message and Generate Response
Feed the retrieved memories and the current message to your LLM (e.g., GPT-4o mini). The agent crafts a reply informed by both present and past. -
Update Memory Base
After responding, add the latest message to MEMS Zero. The pipeline runs: summarize, extract facts, and use the LLM to manage (add, update, delete) memories in the vector database.
Example 1: User Reminder
User: “Remind me to call Sarah tomorrow.” The assistant stores this as a memory, so it can proactively remind the user even days later.
Example 2: Correcting Outdated Information
User: “I moved to Berlin.” The assistant updates the previous “lives in Paris” memory, ensuring future interactions reflect the user’s new location.
Pro Tip: Always test for edge cases, such as users changing their minds or repeating similar information.
Prompt Engineering for Reliable Memory Management
LLM-driven memory management is only as good as your prompts.
The prompts used to extract facts and make memory update decisions are available in MEMS Zero’s GitHub repository. This transparency is a huge advantage, but it also means you need to take responsibility for tuning them.
Example 1: The “Likes Pizza” Problem
If your prompts aren’t clear, the system might keep the “likes pizza” memory even after the user says “I don’t like pizza anymore.” This leads to embarrassing or incorrect responses.
Example 2: Over-Deletion or Over-Retention
Too aggressive prompts might delete useful memories; too lax prompts might keep irrelevant or outdated facts.
Best Practices:
- Test your prompts with diverse user inputs
- Iteratively refine based on where memory management goes wrong
- Involve domain experts when fine-tuning for specialized applications
- Document changes so others understand why certain prompt tweaks were made
Key Point: Prompt engineering is not optional,it’s essential for accuracy and reliability.
Using MEMS Zero: Cloud vs. Open-Source Library
You have two main ways to use MEMS Zero:
- Cloud version (app.memszero.ai)
- Open-source library (self-hosted, customizable)
Cloud Version Pros:
- No setup required,just use the API
- Managed storage and scaling
- Good for rapid prototyping or non-technical teams
- Data stored off-site (potential privacy concerns)
- Limited customization of backend logic
Open-Source Version Pros:
- Full control over storage, prompts, and logic
- Potential for on-premises or private cloud deployment
- Integration with your own vector database (like Qdrant) for true persistence
- Requires setup and maintenance
- By default, without external configuration, memories are stored only in RAM and lost when the session ends
Choosing Between the Two:
- If you value speed and simplicity, start with the cloud
- If you need customizability, privacy, or advanced features, go open-source with persistent storage
Example 1: Start in the Cloud, Move to OSS
A startup prototypes an AI agent on the cloud, then migrates to the open-source version as their needs grow.
Example 2: Enterprise Self-Hosting
A healthcare startup uses the open-source version and Qdrant to ensure patient data stays within their secure infrastructure.
Understanding and Customizing MEMS Zero Prompts
Transparency and customization are core strengths of MEMS Zero.
The framework’s prompts (for summarization, fact extraction, and memory management) are accessible in the GitHub repository. This means you can:
- See exactly how memories are extracted and managed
- Tweak prompts to fit your domain or user base
- Debug or troubleshoot when memory management doesn’t behave as expected
Example 1: Tweaking Fact Extraction for Medical AI
For a healthcare agent, you might adjust prompts to prioritize extracting facts about symptoms or medication changes.
Example 2: Custom Summary for Educational Tutoring
For a tutoring agent, you may want to summarize concepts the student struggled with, rather than just storing all questions.
Best Practice: Document your prompt changes and test with real user data before rolling out to production.
Challenges: Framework Complexity and Abstraction Layers
Abstractions are double-edged swords.
AI libraries that try to support many models and databases through a unified interface often add complexity. This can make it difficult to:
- Access advanced functions of the underlying LLM or vector database
- Debug or extend features beyond what’s exposed in the abstraction layer
Example 1: Difficulty Upgrading Database Features
If Qdrant releases a new search feature but the unified AI library doesn’t support it, you’re stuck unless you hack around the abstraction.
Example 2: Maintenance and Feature Addition Nightmare
Adding a new LLM or database might require changes in multiple layers of code, increasing the risk of bugs and technical debt.
Best Practices:
- Understand the underlying mechanisms of any library you use
- Don’t be afraid to dig deeper, read source code, or even fork the library if needed
- Balance convenience of abstraction with the need for control and extensibility
Key Point: The best AI engineers don’t just use frameworks,they understand how they work “under the hood.”
Case Studies: Applying MEMS Zero in Real-World Scenarios
Let’s look at how MEMS Zero’s memory pipeline can solve practical problems.
Case Study 1: Personal Finance Assistant
A finance bot uses MEMS Zero to remember recurring expenses (“Netflix subscription every month”), user goals (“save $500 by summer”), and updates these as the user’s situation changes. The agent offers more relevant advice by recalling these facts.
Case Study 2: Technical Support Agent
A tech support agent remembers device configurations and previous issues for each user. When a user contacts support, the agent quickly retrieves past troubleshooting steps, saving time and frustration.
Case Study 3: Educational Companion
An ed-tech AI remembers which math topics a student has mastered and which ones they struggle with, adapting lessons accordingly.
Case Study 4: Healthcare Follow-Up
A healthcare assistant recalls patient-reported symptoms or medication side effects from previous visits, ensuring critical information isn’t missed.
Glossary: Key Terms You Need to Know
AI Agent: A system designed to perceive its environment, make decisions, and take actions to achieve specific goals.
Large Language Model (LLM): Deep learning algorithms capable of understanding, summarizing, and generating text.
Memory Layer: The component responsible for storing and managing information from past interactions.
Retrieval Augmented Generation (RAG): A method that combines LLMs with external knowledge retrieval for richer context.
MEMS Zero: The open-source framework for adding long-term memory to AI agents.
Conversation History: The sequence of turns in an AI-user interaction.
User Level Memories: Info specific to a user’s identity, preferences, or history.
Vector Database: Stores and retrieves vector embeddings for efficient similarity search.
Qdrant: An open-source vector database suitable for MEMS Zero.
Semantic Search: Finding relevant memories based on meaning, not just keywords.
Fact Extraction: Identifying key information from a conversation for storage.
Prompt Engineering: Designing inputs to LLMs to get desired outputs and behaviors.
Salient Facts: The most important pieces of information from a conversation.
Scalable Long-Term Reasoning: The ability of the AI to manage and use growing historical knowledge.
Abstraction Layer: Code that hides underlying complexity for a simpler interface.
Quiz: Test Your Understanding
Check your knowledge before moving on.
- What is the primary function of a memory layer in an AI agent system?
- Explain Retrieval Augmented Generation (RAG) and its relation to LLM context.
- How does MEMS Zero claim to differ from OpenAI’s memory implementation?
- Describe the two-phase memory pipeline in MEMS Zero.
- What roles do LLMs play in MEMS Zero’s memory management?
- Where can you find MEMS Zero’s prompts for fact extraction and updates?
- Name the two ways you can use MEMS Zero.
- Where are memories stored in the open-source MEMS Zero without external configuration?
- Why integrate Qdrant with MEMS Zero?
- What’s a challenge with AI libraries that try to unify many models/databases?
Answers: (Review this section above for detailed answers.)
Tips, Pitfalls, and Best Practices for Production-Ready Memory Systems
1. Always Use Persistent Storage for Real Applications
Never rely on in-memory storage for real users,use a vector database like Qdrant for persistence and reliability.
2. Customize Prompts Early
Don’t assume the defaults will work for your domain. Test and refine prompts before launch.
3. Balance Abstraction and Control
Choose frameworks that let you “drop down” into the details when necessary, or be prepared to fork or extend as your use case grows.
4. Monitor and Audit Memory Accuracy
Set up monitoring to catch when memories are stale, incorrect, or missing. User feedback can be invaluable here.
5. Document and Version Your Prompts and Configurations
Treat prompt changes and database configurations as part of your codebase,version, test, and review them regularly.
Conclusion: Building Smarter, More Human-Like AI Agents
Long-term memory is the difference between a useful AI and a truly intelligent assistant.
By leveraging MEMS Zero, integrating persistent vector databases like Qdrant, and mastering prompt engineering, you can build agents that remember, adapt, and provide genuinely helpful experiences. The open nature of MEMS Zero allows you to dive as deep as you need,customizing, evolving, and scaling your memory solution as your application grows.
Key Takeaways:
- LLMs need an external memory layer to deliver real continuity
- MEMS Zero’s two-phase pipeline (summarize, extract facts, manage memory) is a practical, scalable solution
- Persistent storage with a vector database is essential for production
- Prompt engineering is vital,default prompts are just a starting point
- Understanding frameworks deeply enables better, more robust AI systems
Apply these skills and you’ll create AI agents that don’t just talk,they grow, remember, and truly serve their users.
Frequently Asked Questions
This FAQ section is designed to answer the most common and important questions about building long-term memory for AI agents using Python, with a specific focus on frameworks like MEMS zero. It covers foundational concepts, technical approaches, best practices, practical implementation details, and potential challenges,making it a helpful reference for both beginners and those already experienced in deploying AI agents with advanced memory capabilities.
What is the primary challenge that the video addresses regarding AI agents and large language models (LLMs)?
The key challenge is enabling AI agents to have long-term memory that goes beyond the immediate conversation.
While LLMs can follow message order and use Retrieval Augmented Generation (RAG) to pull in external documents, they don't natively remember details about users or previous conversations across sessions. This limitation makes interactions feel less personal and prevents the AI from acting as a true, context-aware agent.
How is long-term memory different from the standard context window or RAG in AI systems?
Long-term memory allows AI agents to recall facts and experiences from past interactions, even across sessions.
The context window holds just the current conversation, and RAG pulls information from external sources for the current session. In contrast, long-term memory is about storing and retrieving information,like user preferences or history,over time. This makes interactions more personalized and effective.
What is MEMS zero and how does it help with building long-term memory for AI agents?
MEMS zero is an open-source framework for adding memory capabilities to AI agents.
It structures the process of capturing, storing, and retrieving user-specific facts. Through a two-phase memory pipeline, it extracts key information from conversation history and saves it in a vector database. This enables efficient, dynamic retrieval and management of long-term memories, making agents more consistent and context-aware.
How does MEMS zero’s two-phase memory pipeline work?
The two-phase pipeline extracts and manages memory in two main steps.
First, MEMS zero processes conversation history to generate a summary and extract important facts or “memories.” In the second phase, another LLM decides if these should be added as new entries, update existing ones, or remove outdated information in the vector database. This keeps the AI’s memory accurate and relevant over time.
Can developers customize how MEMS zero extracts and updates memories?
Yes, MEMS zero is open source and highly customizable.
Developers can modify the prompts used for fact extraction and memory management, allowing them to adapt the system to different use cases and fine-tune what information is stored or updated. This flexibility is valuable for tailoring the agent’s memory to specific business needs.
Does MEMS zero require using a specific database or LLM provider?
No, MEMS zero is designed to be flexible regarding LLMs and databases.
While the default examples use OpenAI and Qdrant (an open-source vector database), developers can configure MEMS zero to work with various LLM providers and vector databases by adjusting the configuration settings.
What are the benefits of using a framework like MEMS zero for adding long-term memory compared to simply storing all conversation history?
MEMS zero is more scalable and efficient than just storing entire conversation histories.
Storing every message increases storage needs, latency, and token costs. MEMS zero summarizes and extracts key pieces of information, storing only what’s essential. This approach improves performance and reduces operational costs without sacrificing context or personalization.
What is a key challenge to be aware of when using AI libraries and frameworks like MEMS zero?
High-level frameworks add abstraction, which can hide important details from developers.
This makes initial setup easier but can limit access to specific features or methods of underlying components, complicating customization and troubleshooting. Understanding how the abstraction layers work and occasionally working directly with the lower-level APIs can help mitigate these issues.
What is the primary function of a memory layer in an AI agent system?
The memory layer stores information about past interactions, user identity, and preferences.
This allows the AI agent to reference previous conversations and deliver more relevant, personalized responses over time,much like a human remembering details about a friend or colleague.
What is Retrieval Augmented Generation (RAG) and how does it relate to expanding context for LLMs?
RAG combines LLMs with external retrieval systems to provide richer context.
Instead of relying solely on what’s in the current prompt, RAG fetches relevant documents or facts from a knowledge base and injects them into the LLM’s input. For memory, RAG can pull up user-specific information or prior interactions, making the AI’s responses more informed.
How does MEMS zero claim to differ from OpenAI’s current memory implementation in terms of performance?
MEMS zero claims to outperform OpenAI’s native memory implementation according to its research paper.
By focusing on efficient extraction, consolidation, and retrieval of key facts, MEMS zero provides faster access to relevant information and scales better as the volume of stored memories grows.
What role do Large Language Models (LLMs) play within the MEMS zero memory management system beyond the initial interaction?
LLMs in MEMS zero are used for summarizing, fact extraction, and dynamic memory management.
They help decide whether to add, update, or delete memories based on summaries of conversation histories and retrievals. This enables ongoing refinement and improvement of the agent's long-term memory.
Where can developers find information about the prompts used by MEMS zero for tasks like fact extraction and memory updates?
Developers can access all prompt templates in MEMS zero’s GitHub repository.
This transparency enables easy customization and adaptation of the framework to fit specific business or technical requirements.
What are the two ways a developer can use MEMS zero?
MEMS zero can be used via a cloud platform or as an open-source package.
The cloud platform offers managed infrastructure, while the open-source version gives developers full control over customization and deployment.
When using the open-source version of MEMS zero without external configurations, where are memories stored, and what happens to them when the session ends?
Memories are stored in local RAM and are lost when the session ends.
To persist data across sessions, developers need to connect MEMS zero to an external vector database.
What is the purpose of configuring a vector database like Qdrant with the open-source MEMS zero?
A vector database enables persistent, efficient storage and retrieval of memories.
By connecting to a database like Qdrant, agents can retain long-term memory across sessions, supporting advanced use cases such as multi-session conversations or personalized recommendations.
What is one potential challenge with using comprehensive AI libraries that support many different models and databases?
Unified interfaces can obscure access to specific features of individual models or databases.
This can limit fine-grained control, making it harder to optimize or troubleshoot specific components. Careful design choices and a deep understanding of the underlying systems are needed to balance simplicity and flexibility.
Why is long-term memory important for AI agents and user experience?
Long-term memory allows AI agents to build relationships and deliver personalized, consistent interactions.
For example, a virtual assistant that remembers your travel preferences can proactively suggest flights or hotels. This greatly enhances user trust, engagement, and satisfaction.
How does storing simple message history compare to using a memory framework for long-term reasoning?
Simple message history is limited to recent interactions and can’t scale for deep personalization.
A memory framework like MEMS zero extracts and stores meaningful facts, enabling the agent to reason over a large body of historical context efficiently,similar to how a CRM system summarizes key client notes for quick reference.
What is fact extraction and why is it important in long-term memory systems?
Fact extraction identifies key information from conversations for storage as long-term memory.
For example, if a customer mentions their birthday or a product preference, fact extraction ensures that detail is available for future interactions, improving personalization.
What is the role of semantic search and vector databases in long-term memory systems?
Semantic search uses vector embeddings to find relevant memories based on meaning, not just keywords.
Vector databases allow fast, efficient retrieval of similar information, making it possible for AI agents to recall past facts even if the query wording changes.
How does prompt engineering impact memory extraction and management in AI agents?
Well-designed prompts guide LLMs to extract and manage memories more reliably.
Improved prompt phrasing can reduce errors, ensure important details are captured, and minimize misinterpretations,vital for business applications where accuracy matters.
How does dynamic memory management (add, update, delete) contribute to scalable long-term reasoning?
Dynamic management ensures only relevant, up-to-date, and non-redundant information is stored.
By continually adding new facts, updating existing ones, and removing outdated memories, the system avoids information overload and keeps responses timely and accurate.
What are the advantages and disadvantages of using the cloud vs. open-source versions of MEMS zero?
The cloud version offers managed infrastructure and scalability, reducing operational overhead.
However, it may have restrictions on customization and data control. The open-source version gives full flexibility but requires more setup and maintenance. The choice depends on your team's needs, technical expertise, and data privacy requirements.
What are the implications of relying on LLMs to decide when to add, update, or delete memories?
LLMs can sometimes misinterpret context or make inconsistent decisions, leading to incomplete or incorrect memory updates.
Prompt engineering, validation checks, and combining rule-based logic with LLM outputs can help improve reliability. For example, testing prompts on diverse conversations can surface edge cases.
What are common business use cases for AI agents with long-term memory?
Key applications include customer support, sales automation, personal assistants, and learning platforms.
For instance, a support bot that remembers previous issues can resolve tickets faster, or a sales AI that recalls customer preferences can tailor offers and improve conversion rates.
How do you scale long-term memory systems for large user bases?
Efficient storage (via vector databases), fact extraction, and regular pruning are critical for scalability.
Batch processing, sharding, and caching can also help. For example, a SaaS platform might partition memories by user ID to distribute load and ensure fast access.
How do you handle privacy and data security when storing user memories?
Encrypt sensitive data, implement access controls, and comply with regulations like GDPR.
Anonymizing personal identifiers and allowing users to view or delete their stored information are also best practices for responsible memory management.
What are typical challenges or pitfalls when implementing long-term memory for AI agents?
Common pitfalls include memory bloat, privacy risks, inconsistent memory updates, and lack of transparency.
Testing with real-world data, monitoring memory usage, and providing clear audit trails can help avoid these issues.
How can long-term memory frameworks like MEMS zero be integrated into existing Python applications?
These frameworks can be added as standalone modules or middleware layers between the AI interface and your backend.
For instance, a Django or Flask app can call MEMS zero APIs after each interaction to store or retrieve user memories.
Can you give an example of how memory summarization improves performance?
Instead of storing a full chat transcript, a summary might record: “User prefers vegetarian meals and travels frequently to London.”
Retrieving this concise summary is faster and more relevant for future conversations, saving compute resources and providing instant context.
What strategies can be used to prevent memory loss or corruption in AI agent systems?
Use persistent storage (like vector databases), automatic backups, and regular data validation checks.
For critical business data, implement redundancy and monitoring to detect and recover from memory issues quickly.
How do you balance the convenience of high-level frameworks with the need for fine control in production applications?
Start with high-level frameworks for rapid prototyping, then selectively “drop down” to lower-level APIs for key optimizations or custom logic.
For large-scale or sensitive deployments, invest time in understanding the abstractions and extending them only where necessary.
How should you test the performance and reliability of long-term memory systems?
Simulate real-world conversations, measure retrieval speed, and check memory accuracy under load.
Automated testing tools and periodic audits help catch regressions and ensure the system scales as user numbers grow.
What trends or future developments are expected in AI agent memory management?
Expect continued improvements in fact extraction algorithms, hybrid storage models, and privacy-preserving memory techniques.
There’s a growing focus on user-controlled memory and explainable AI, so agents can clarify what they remember and why.
Where can I learn more about building and managing long-term memory in AI agents?
Explore open-source repositories, technical blogs, research papers, and community forums.
For MEMS zero, the official GitHub and documentation are good starting points. Industry case studies and AI/ML conferences also regularly discuss best practices and new approaches.
Certification
About the Certification
Get certified in Building Persistent Memory for AI Agents with Python and MEMS Zero. Demonstrate your ability to create context-aware AI assistants that recall user data, adapt interactions, and deliver smarter, more personalized support.
Official Certification
Upon successful completion of the "Certification in Implementing Long-Term Memory for AI Agents with Python and MEMS Zero", you will receive a verifiable digital certificate. This certificate demonstrates your expertise in the subject matter covered in this course.
Benefits of Certification
- Enhance your professional credibility and stand out in the job market.
- Validate your skills and knowledge in cutting-edge AI technologies.
- Unlock new career opportunities in the rapidly growing AI field.
- Share your achievement on your resume, LinkedIn, and other professional platforms.
How to complete your certification successfully?
To earn your certification, you’ll need to complete all video lessons, study the guide carefully, and review the FAQ. After that, you’ll be prepared to pass the certification requirements.
Other AI Video Courses

Video Course: What is Generative AI and how does it work?

Video Course: How to Use ChatGPT from Beginner to Professional

Video Course: How to Use Google Gemini for Google Workspace to Boost Productivity

Video Course: How to Use Claude 3.7 AI - Tips for Beginners!

Video Course: ChatGPT for Data Analytics: Full Course - from Beginners to Professional

Video Course: Generating Images and photos With ChatGPT?

Video Course: Generating Images & Photo's with MidJourney

Video Course: Generating Design's with Microsoft Designer and AI

Video Course: Generating Design's with Canva.com and AI
Join 20,000+ Professionals, Using AI to transform their Careers
Join professionals who didn’t just adapt, they thrived. You can too, with AI training designed for your job.







